All dynamic applications need to prevent caching so that the request actually reaches the server each time.
In this post, I found over the internet, a good explanation of the different cache headers was given. Snippet from the post:
First of all you have to remember that these directives are used by all downstream caches (proxy servers and the browser) and therefore what might work in one situation (say, a direct connection between web server and client) may not work if there is a caching proxy server in between if the cache control headers are not thought through carefully.
Taking the directives in turn:
response.setHeader("Pragma", "no-cache");
This is the only cache control directive for HTTP 1.0, so should feature in addition to any HTTP 1.1 cache control headers you include.
response.setHeader("Cache-Control", "no-cache"); // HTTP 1.1
This directive does NOT prevent caching despite its name. It allows caching of the page, but specifies that the cache must ask the originating web server if the page is up-to-date before serving the cached version. So the cached page can still be served up i- f the originating web server says so. Applies to all caches.
response.setDateHeader ("Expires", 0); // HTTP 1.1
This tells the browser that the page has expired and must be treated as stale. Should be good news as long as the caches obey.
response.setHeader("Cache-Control", "private"); // HTTP 1.1
This specifies that the page contains information intended for a single user only and must not be cached by a shared cache (e.g. a proxy server).
response.setHeader("Cache-Control", "no-store"); // HTTP 1.1
This specifies that a cache must NOT store any part of the response or the request that elicited it. Adding these two headers should prevent the caching of pages anywhere between the web server and browser, as well as in the browser itself. The meaning of each directive is very specific and so a given combination of directives has a different effect in any one environment.
Friday, December 29, 2006
Showing Modal windows in HTML Browsers
It had always been a challenge for web developers to show modal dialog boxes using Javascript that works across all browsers.
IE has a proprietary javascript method called 'showModalDialog', where as FireFox accepts an 'modal' attribute in the window.open function. Here's a sample code for the same:
function modalWin()
{
if (window.showModalDialog)
{window.showModalDialog("xpopupex.htm","name",
"dialogWidth:255px;dialogHeight:250px");}
else
{window.open('xpopupex.htm','name','height=255,width=250,toolbar=no,
directories=no,status=no,menubar=no,
scrollbars=no,resizable=no ,modal=yes');}
}
But there still remains one more problem. How to disable the close button in the dialog. There is no support in JS for that, hence the simple answer is that NO-it cannot be done.
But we can write our own custom dialog. An example of the same is given here:
http://javascript.about.com/library/blmodald1.htm But this involved a lot of work.
Being lazy, I was looking for a out-of-box solution and my prayers were answered - The Yahoo widget UI library. This is one of the coolest AJAX, DHTML library I have seen in years and its FREE for all use.
The Yahoo UI Library has a SimpleDialog Component that can be made modal and also the close button on the header can be disabled. Also the control is very simple to use.
http://developer.yahoo.com/yui/container/simpledialog/
IE has a proprietary javascript method called 'showModalDialog', where as FireFox accepts an 'modal' attribute in the window.open function. Here's a sample code for the same:
function modalWin()
{
if (window.showModalDialog)
{window.showModalDialog("xpopupex.htm","name",
"dialogWidth:255px;dialogHeight:250px");}
else
{window.open('xpopupex.htm','name','height=255,width=250,toolbar=no,
directories=no,status=no,menubar=no,
scrollbars=no,resizable=no ,modal=yes');}
}
But there still remains one more problem. How to disable the close button in the dialog. There is no support in JS for that, hence the simple answer is that NO-it cannot be done.
But we can write our own custom dialog. An example of the same is given here:
http://javascript.about.com/library/blmodald1.htm But this involved a lot of work.
Being lazy, I was looking for a out-of-box solution and my prayers were answered - The Yahoo widget UI library. This is one of the coolest AJAX, DHTML library I have seen in years and its FREE for all use.
The Yahoo UI Library has a SimpleDialog Component that can be made modal and also the close button on the header can be disabled. Also the control is very simple to use.
http://developer.yahoo.com/yui/container/simpledialog/
Thursday, December 28, 2006
Dealing with currency calculations
Many novice developers use 'float' and 'double' data-types to represent dollars and cents. This is dangerous as float/double calculations always involve rounding off and precision errors.
More info can be found at the following links:
http://www-128.ibm.com/developerworks/java/library/j-jtp0114/
http://www.javaworld.com/cgi-bin/mailto/x_java.cgi
http://en.wikipedia.org/wiki/IEEE_754
Currency values require exactness. Hence use the 'BigDecimal' class in Java for handling currencies. Here is some code snippet:
//Get the base value of the policy and store it in a BigDecimal object
BigDecimal d = new BigDecimal("1115.32");
//get the extra's multiplier from database
BigDecimal multiplier = new BigDecimal("0.0049");
//Do the multiplication - use methods of Big Decimal
BigDecimal d2 = d.multiply(multiplier);
System.out.println("Unformatted no scale: " + d2.toString());
//Set the scale (2 decimal places) and round-off mode
d2 = d2.setScale(2, BigDecimal.ROUND_HALF_UP);
System.out.println("Unformatted with scale: " + d2.toString());
NumberFormat n = NumberFormat.getCurrencyInstance(Locale.UK);
double money = d2.doubleValue();
String s = n.format(money);
System.out.println("Formatted: " + s);
More info can be found at the following links:
http://www-128.ibm.com/developerworks/java/library/j-jtp0114/
http://www.javaworld.com/cgi-bin/mailto/x_java.cgi
http://en.wikipedia.org/wiki/IEEE_754
Currency values require exactness. Hence use the 'BigDecimal' class in Java for handling currencies. Here is some code snippet:
//Get the base value of the policy and store it in a BigDecimal object
BigDecimal d = new BigDecimal("1115.32");
//get the extra's multiplier from database
BigDecimal multiplier = new BigDecimal("0.0049");
//Do the multiplication - use methods of Big Decimal
BigDecimal d2 = d.multiply(multiplier);
System.out.println("Unformatted no scale: " + d2.toString());
//Set the scale (2 decimal places) and round-off mode
d2 = d2.setScale(2, BigDecimal.ROUND_HALF_UP);
System.out.println("Unformatted with scale: " + d2.toString());
NumberFormat n = NumberFormat.getCurrencyInstance(Locale.UK);
double money = d2.doubleValue();
String s = n.format(money);
System.out.println("Formatted: " + s);
Wednesday, December 27, 2006
Javascript: Conditional Comments and Conditional Compilation
Recently came across some cool new features of Javascript that reduced the amount of coding required. For many years, developers have been writing Javascript code to detect the browser type and accordingly fire javascript functions or do a document.write()
But now there are more developer-friendly ways of detecting the browser type and handling content.
Conditional Comments: These look like HTML comments, but IE browsers treat them differently.
For e.g.
<!--[if IE]>You are using IE (IE5+ and above).<![endif]-->
The above line would be rendered only if the browser is IE.
To render something if the browser in non-IE use the following:
<![if !IE]>You are NOT using IE.<![endif]>
We can also check the IE version number:
<!--[if IE 6]>You are using IE 6!<![endif]-->
Another feature of IE is Conditional Compilation. Non-IE browsers would ignore the @cc block
/*@cc_on
/*@if (@_win32)
document.write("OS is 32-bit, browser is IE.");
@else @*/
document.write("Browser is not IE (ie: is Firefox) or Browser is not 32 bit IE.");
/*@end@*/
But now there are more developer-friendly ways of detecting the browser type and handling content.
Conditional Comments: These look like HTML comments, but IE browsers treat them differently.
For e.g.
<!--[if IE]>You are using IE (IE5+ and above).<![endif]-->
The above line would be rendered only if the browser is IE.
To render something if the browser in non-IE use the following:
<![if !IE]>You are NOT using IE.<![endif]>
We can also check the IE version number:
<!--[if IE 6]>You are using IE 6!<![endif]-->
Another feature of IE is Conditional Compilation. Non-IE browsers would ignore the @cc block
/*@cc_on
/*@if (@_win32)
document.write("OS is 32-bit, browser is IE.");
@else @*/
document.write("Browser is not IE (ie: is Firefox) or Browser is not 32 bit IE.");
/*@end@*/
Wednesday, December 20, 2006
Beware of using Application Context in a WAS clustered environment
Websphere 6.1 Network Deployment App Server Package provides out-of-the-box support for clustering, thus providing for fail-over and load-balancing.
In a cluster, WAS provides data-replication services for 'session' data, 'WAS dynamic cache' data, etc. across member in a cluster.
But it does not provide replication of objects stored in the Application context or Servlet Context across the nodes of the cluster.
Hence if Ur application relies on state stored in the App Context, then it would fail in a cluster unless U make sure that all the concerned requests (which expect objects in the context) have the same JSESSIONID cookie and session affinity is configured on WAS. In this case, the WAS infrastructure would consider the jsession id present in the request and forward the request to the appropriate Appserver.
Another solution is to use a database or a file and not the Servlet Context for storing data to be shared across sessions.
In a cluster, WAS provides data-replication services for 'session' data, 'WAS dynamic cache' data, etc. across member in a cluster.
But it does not provide replication of objects stored in the Application context or Servlet Context across the nodes of the cluster.
Hence if Ur application relies on state stored in the App Context, then it would fail in a cluster unless U make sure that all the concerned requests (which expect objects in the context) have the same JSESSIONID cookie and session affinity is configured on WAS. In this case, the WAS infrastructure would consider the jsession id present in the request and forward the request to the appropriate Appserver.
Another solution is to use a database or a file and not the Servlet Context for storing data to be shared across sessions.
Monday, October 23, 2006
java.lang.error - Unresolved Compilation problem
Most of us have encounted this error when working with JSP pages. If JSP pages are compiled on the fly, then it is possible that errors are present in it that cannot be resolved at runtime. Hence it is a good idea to compile your JSPs as U develop them. Most of the modern IDE's have support for compiling JSP's during the 'build' process.
Recently I encountered the same error while building a web application on Netbeans. I was getting the "java.lang.error - Unresolved compilation problem" for a Struts Action class, that was referencing another bean. It was strange that this error was not caught by the compiler. I did a 'clean build' again and everything was OK. But still at runtime, I got the same error.
I was perplexed and could not understand what was the problem.
Then suddenly inbetween, I started getting ClassCastExceptions. It was then I reliazed that there was older classes in the classpath somewhere, that was messing things up.
Closer inspection revealed that someone had placed "classfiles" into source-control (VSS) and when we did 'get-latest', the old class files were also downloaded into our directory.
Moral of the story: Whenever U get ClassCastExceptions or Unresolved Compilation problems at runtime, check if U have stale class files somewhere in the classpath.
Recently I encountered the same error while building a web application on Netbeans. I was getting the "java.lang.error - Unresolved compilation problem" for a Struts Action class, that was referencing another bean. It was strange that this error was not caught by the compiler. I did a 'clean build' again and everything was OK. But still at runtime, I got the same error.
I was perplexed and could not understand what was the problem.
Then suddenly inbetween, I started getting ClassCastExceptions. It was then I reliazed that there was older classes in the classpath somewhere, that was messing things up.
Closer inspection revealed that someone had placed "classfiles" into source-control (VSS) and when we did 'get-latest', the old class files were also downloaded into our directory.
Moral of the story: Whenever U get ClassCastExceptions or Unresolved Compilation problems at runtime, check if U have stale class files somewhere in the classpath.
Friday, September 15, 2006
ClassLoaders and Packaging - J2EE Servers
I bet there is not a single J2EE developer who has not had nightmares trying to solve problems regarding ClassCastException when the J2EE application is deployed on the AppServer.
Resolving such problems require a sound knowledge of Java ClassLoading mechanism. In my previous post here, I had described the class loader heirarchy of standard JRE.
After this, we need to understand the class-loading mechanisms of the J2EE AppServer we are using. The classloading mechanisms of different appservers are different and also highly configurable through configuration files of the appserver. For e.g. make the classloaders execute child-first loading or the default parent-first loading, configure the same classloader for all modules in a ear file, etc.
Here is a good article that explains the fundamentals of ClassLoading in some J2EE servers:
http://www.theserverside.com/tt/articles/article.tss?l=ClassLoading
Resolving such problems require a sound knowledge of Java ClassLoading mechanism. In my previous post here, I had described the class loader heirarchy of standard JRE.
After this, we need to understand the class-loading mechanisms of the J2EE AppServer we are using. The classloading mechanisms of different appservers are different and also highly configurable through configuration files of the appserver. For e.g. make the classloaders execute child-first loading or the default parent-first loading, configure the same classloader for all modules in a ear file, etc.
Here is a good article that explains the fundamentals of ClassLoading in some J2EE servers:
http://www.theserverside.com/tt/articles/article.tss?l=ClassLoading
Alternatives to Apache webserver
Learned about some new webservers that claim to be faster than Apache and can handle more traffic under heavy load:
http://www.acme.com/software/thttpd/
http://www.lighttpd.net/
These servers are being used for heavy traffic websites and its definately worth evalauting them.
http://www.acme.com/software/thttpd/
http://www.lighttpd.net/
These servers are being used for heavy traffic websites and its definately worth evalauting them.
ArrayList Vs LinkedList
The Java SDK contains 2 implementations of the List interface - ArrayList and LinkedList.A common design dilemma for developers is when to use what ?
Some basics first:
An arraylist used an array for internal storage. This means it's fast for random access (e.g. get me element #999), because the array index gets you right to that element. But then adding and deleting at the start and middle of the arraylist would be slow, because all the later elements have to copied forward or backward. (Using System.arrayCopy())
ArrayList would also give a performance issue when the internal array fills up. The arrayList has to create a new array and copy all the elements there. The ArrayList has a growth algorithm of (n*3)/2+1, meaning that each time the buffer is too small it will create a new one of size (n*3)/2+1 where n is the number of elements of the current buffer. Hence if we can guess the number of elements that we are going to have, then it makes sense to create a arraylist with that capacity during object creation (using the overloaded construtor or ArrayList)
LinkedList is made up of a chain of nodes. Each node stores an element and the pointer to the next node. A singly linked list only has pointers to next. A doubly linked list has a pointer to the next and the previous element. This makes walking the list backward easier.
Linked lists are slow when it comes to random access. Gettting element #999 means you have to walk either forward from the beginning or backward from the end (depending on whether 999 is less than or greater than half the list size), calling next or previous, until you get to that element.Linked lists are fast for inserts and deletes anywhere in the list, since all you do is update a few next and previous pointers of a node. Each element of a linked list (especially a doubly linked list) uses a bit more memory than its equivalent in array list, due to the need for next and previous pointers.
Ok. Cool...Now that the fundamentals are clear, let's conclude on when to use what:
Here is a snippet from SUN's site.
The Java SDK contains 2 implementations of the List interface - ArrayList and LinkedList.
If you frequently add elements to the beginning of the List or iterate over the List to delete elements from its interior, you should consider using LinkedList. These operations require constant-time in a LinkedList and linear-time in an ArrayList. But you pay a big price in performance. Positional access requires linear-time in a LinkedList and constant-time in an ArrayList.
Here are a few more links that give interesting perspectives:
http://www.javaspecialists.co.za/archive/Issue111.html
http://joust.kano.net/weblog/archives/000066.html
http://soft.killingar.net/documents/LinkedList+vs+ArrayList
http://jira.jboss.com/jira/browse/JBXB-65
Some basics first:
An arraylist used an array for internal storage. This means it's fast for random access (e.g. get me element #999), because the array index gets you right to that element. But then adding and deleting at the start and middle of the arraylist would be slow, because all the later elements have to copied forward or backward. (Using System.arrayCopy())
ArrayList would also give a performance issue when the internal array fills up. The arrayList has to create a new array and copy all the elements there. The ArrayList has a growth algorithm of (n*3)/2+1, meaning that each time the buffer is too small it will create a new one of size (n*3)/2+1 where n is the number of elements of the current buffer. Hence if we can guess the number of elements that we are going to have, then it makes sense to create a arraylist with that capacity during object creation (using the overloaded construtor or ArrayList)
LinkedList is made up of a chain of nodes. Each node stores an element and the pointer to the next node. A singly linked list only has pointers to next. A doubly linked list has a pointer to the next and the previous element. This makes walking the list backward easier.
Linked lists are slow when it comes to random access. Gettting element #999 means you have to walk either forward from the beginning or backward from the end (depending on whether 999 is less than or greater than half the list size), calling next or previous, until you get to that element.Linked lists are fast for inserts and deletes anywhere in the list, since all you do is update a few next and previous pointers of a node. Each element of a linked list (especially a doubly linked list) uses a bit more memory than its equivalent in array list, due to the need for next and previous pointers.
Ok. Cool...Now that the fundamentals are clear, let's conclude on when to use what:
Here is a snippet from SUN's site.
The Java SDK contains 2 implementations of the List interface - ArrayList and LinkedList.
If you frequently add elements to the beginning of the List or iterate over the List to delete elements from its interior, you should consider using LinkedList. These operations require constant-time in a LinkedList and linear-time in an ArrayList. But you pay a big price in performance. Positional access requires linear-time in a LinkedList and constant-time in an ArrayList.
Here are a few more links that give interesting perspectives:
http://www.javaspecialists.co.za/archive/Issue111.html
http://joust.kano.net/weblog/archives/000066.html
http://soft.killingar.net/documents/LinkedList+vs+ArrayList
http://jira.jboss.com/jira/browse/JBXB-65
Monday, September 11, 2006
Info about Credit Cards
There are always new wonderful things that U learn - things that never caught Ur attention.
I found out a few interesting things about credit card numbers recently.
Did U know that all VISA/MasterCard credit card numbers start with "4" ???
Did U know that it is possible to do basic validation of a credit card number without even hitting any database ???
For more such interesting things about Credit cards, follow these links:
http://www.merriampark.com/anatomycc.htm
http://euro.ecom.cmu.edu/resources/elibrary/everycc.htm
I found out a few interesting things about credit card numbers recently.
Did U know that all VISA/MasterCard credit card numbers start with "4" ???
Did U know that it is possible to do basic validation of a credit card number without even hitting any database ???
For more such interesting things about Credit cards, follow these links:
http://www.merriampark.com/anatomycc.htm
http://euro.ecom.cmu.edu/resources/elibrary/everycc.htm
Reload of Struts-config file
In earlier versions of Struts (v1.0), there was a ReloadAction that allowed us to reload the struts-config file from disk without reloading the web application or restarting the server.
But since Struts 1.1, this Action was removed. So it was no longer possible to reload the struts-config file using any in-built capabilities. I could not understand why this had been done. Finally a post by Craig R. McClanahan (founder of Struts) resolved all doubts:
ReloadAction is not supported in 1.1 for two reasons:
* It never did let you reload everything that you would really want to -- particularly changed classes -- so many people ended up having to reload the webapp anyway.
* Not supporting ReloadAction lets Struts avoid doing synchronization locks around all the lookups (like figuring out which action to use, or the detination of an ActionForward) so apps can run a little faster.
But under ordinary conditions, if we reload the webapp, then all sessions are lost - atleast that's what I thought; but I was wrong. Looks like the session is kept alive, but all session objects are destroyed unless they implement the 'Serializable' interface. I found this out from another post of Craig.
You can avoid webapp reload problems (which will likely be requiredfor *any* server, not just Tomcat) by following a couple of simple rules:
* For session attributes, make sure that they implement java.io.Serializable (and that any classes used in instance variables are also Serializable). Tomcat 4+, at least, will save and restore these sessions and their attributes for you.
* For context attributes, make sure that your webapp startup procedures properly restore anything that needs to be there. For a servlet 2.3 or later container, the proper way to do this is with a class that implements ServletContextListener, regsitered in a element in your web.xml file.
Proper application architecture will avoid any reloadability problems.
But since Struts 1.1, this Action was removed. So it was no longer possible to reload the struts-config file using any in-built capabilities. I could not understand why this had been done. Finally a post by Craig R. McClanahan (founder of Struts) resolved all doubts:
ReloadAction is not supported in 1.1 for two reasons:
* It never did let you reload everything that you would really want to -- particularly changed classes -- so many people ended up having to reload the webapp anyway.
* Not supporting ReloadAction lets Struts avoid doing synchronization locks around all the lookups (like figuring out which action to use, or the detination of an ActionForward) so apps can run a little faster.
But under ordinary conditions, if we reload the webapp, then all sessions are lost - atleast that's what I thought; but I was wrong. Looks like the session is kept alive, but all session objects are destroyed unless they implement the 'Serializable' interface. I found this out from another post of Craig.
You can avoid webapp reload problems (which will likely be requiredfor *any* server, not just Tomcat) by following a couple of simple rules:
* For session attributes, make sure that they implement java.io.Serializable (and that any classes used in instance variables are also Serializable). Tomcat 4+, at least, will save and restore these sessions and their attributes for you.
* For context attributes, make sure that your webapp startup procedures properly restore anything that needs to be there. For a servlet 2.3 or later container, the proper way to do this is with a class that implements ServletContextListener, regsitered in a
Proper application architecture will avoid any reloadability problems.
Tuesday, August 15, 2006
Using java.ext.dirs to ease setting classpath
If U are in a hurry to compile code and there is a big list of Jar files to include in the classpath, there U don't have to struggle to include the names of all the jar's in the classpath.
There is a neat trick - use the "java.ext.dirs" JVM param to point to the directory containing the jar files.
java -Djava.ext.dirs=c:\java\axis-1_1\lib -classpath classes MyJavaClass
There is a neat trick - use the "java.ext.dirs" JVM param to point to the directory containing the jar files.
java -Djava.ext.dirs=c:\java\axis-1_1\lib -classpath classes MyJavaClass
Prevent web images from being saved.
Many novice web-developers struggle with the idea of preventing users from stealing the images present on a HTML page.
The truth is that it is impossible to prevent the user from saving the images on a HTML page.
We can watermark them and prove that they belong to us and enter comments that say this in clear text, but it still doesn't keep people from issuing an HTTP request and saving the image.
The truth is that it is impossible to prevent the user from saving the images on a HTML page.
We can watermark them and prove that they belong to us and enter comments that say this in clear text, but it still doesn't keep people from issuing an HTTP request and saving the image.
Funny thing about URL's
Recently after years of web-programming I noticed a subtle thing.
Whenever we make a request for a website, say http://narencoolgeek.blogspot.com, the URL in the browser changes to http://narencoolgeek.blogspot.com/ . (Notice the forward slash at the end of the URL)
I put in a sniffer to see what is exactly happening. The server on receiving the first URL sends a 301/302 (temporary moved) response redirecting the client to the new URL. Why is this necessary? Maybe some legacy reason, or maybe this is necessary to pick up the default page of the website directory.
Whenever we make a request for a website, say http://narencoolgeek.blogspot.com, the URL in the browser changes to http://narencoolgeek.blogspot.com/ . (Notice the forward slash at the end of the URL)
I put in a sniffer to see what is exactly happening. The server on receiving the first URL sends a 301/302 (temporary moved) response redirecting the client to the new URL. Why is this necessary? Maybe some legacy reason, or maybe this is necessary to pick up the default page of the website directory.
Sorting objects in a Java collection
We all have felt the need to sort our custom objects based on the value of ainstance varaible of that object..For e.g. sorting of a Vector of AddressCard objects according to theDisplayName.i.e Consider the following class:
class AddressCard{ public String sDisplayName; // Other instance variables.}
Now say we want to sort a Vector of AddressCard objects according to the valueof sDisplayName.Though we can write a custom sorting mechanism for this, we have another neatsolution which requires miminal coding.We make use of the TreeMap object as follows, which is sorted internally..Given below is the code snippet.
//Instantiate a TreeMap object....If Case sensitive is desired, use a emptyconstructor.
TreeMap tMap = new TreeMap(String.CASE_INSENSITIVE_ORDER);
//keep on adding the object's field (to be sorted) as the key and the object reference as the value.
for loop:
tMap.put(sDisplayName, AddressCardObject);
//-------------------end of for loop
Once all the objects have been entered into the TreeMap, they are sorted automatically..So if U want the sorted Vector ofobjects then just do the following:
Collection c = tMap.values();
Vector v = new Vector(c); //Pass the collection in the constructor.
And Voila !!!....we have a sorted Vector of objects sorted according to therequired field...and that too in just 4-5 lines of code.
class AddressCard{ public String sDisplayName; // Other instance variables.}
Now say we want to sort a Vector of AddressCard objects according to the valueof sDisplayName.Though we can write a custom sorting mechanism for this, we have another neatsolution which requires miminal coding.We make use of the TreeMap object as follows, which is sorted internally..Given below is the code snippet.
//Instantiate a TreeMap object....If Case sensitive is desired, use a emptyconstructor.
TreeMap tMap = new TreeMap(String.CASE_INSENSITIVE_ORDER);
//keep on adding the object's field (to be sorted) as the key and the object reference as the value.
for loop:
tMap.put(sDisplayName, AddressCardObject);
//-------------------end of for loop
Once all the objects have been entered into the TreeMap, they are sorted automatically..So if U want the sorted Vector ofobjects then just do the following:
Collection c = tMap.values();
Vector v = new Vector(c); //Pass the collection in the constructor.
And Voila !!!....we have a sorted Vector of objects sorted according to therequired field...and that too in just 4-5 lines of code.
Why execute() replaced perform() in Struts
Recently a friend of mine asked me why the "perform()" method in Struts was replaced with the "execute()" method?
A closed look at the signatures of the two methods revealed that the "execute()" method throws java.lang.Exception whereas the old "perform()" method throws IOException and ServletException.
This new execute method was necessary because of this reason. Due to the declarative exception handling that has been added,the framework needs to catch all instances of java.lang.Exception from theAction class.
Instead of changing the method signature for the perform() method and breakingbackwards compatibility, the execute() method was added.
Currently, the execute() method just turns around and invokes the perform() method anyway.
A closed look at the signatures of the two methods revealed that the "execute()" method throws java.lang.Exception whereas the old "perform()" method throws IOException and ServletException.
This new execute method was necessary because of this reason. Due to the declarative exception handling that has been added,the framework needs to catch all instances of java.lang.Exception from theAction class.
Instead of changing the method signature for the perform() method and breakingbackwards compatibility, the execute() method was added.
Currently, the execute() method just turns around and invokes the perform() method anyway.
Thursday, July 27, 2006
Diff btw Cache and History in Browsers
Cache is the segment of the physical hard-disk that stores the web resources that we browse.
For IE, the folder for cache is "Temporary Internet Files"
History is just a stack of URL's that the user has visited (For a number of days). The state of the page is not stored in History. If U open IE options dialog box, then U will see different settings for Temporary Internet Files and History.
So what happens when the user presses the back button?
The browser uses a stack (History) to remember visited pages. Each time a link is followed, or the user gives an URL to retrieve, the browser will push the current URL on its stack. If the user selects the back function of his browser, the browser will go to the document whose URL is saved on the top of the stack (if the stack is non empty) and will pop the URL from the stack.
If the URL resource can be obtained from the cache, then the browser does so, otherwise a fresh request is made.
Hence even if we disable cache thru response headers, the user can still click back and reload the page from the server. But the current state on the server may not be 'ready' for that request.
There are many strategies that can be used to disable back: Remove the top bar of the browser thru javascript, write a javascript function that will get executed on page load and reset the history stack etc.
On the server side, we can use the "Synchronizer Token pattern"
For IE, the folder for cache is "Temporary Internet Files"
History is just a stack of URL's that the user has visited (For a number of days). The state of the page is not stored in History. If U open IE options dialog box, then U will see different settings for Temporary Internet Files and History.
So what happens when the user presses the back button?
The browser uses a stack (History) to remember visited pages. Each time a link is followed, or the user gives an URL to retrieve, the browser will push the current URL on its stack. If the user selects the back function of his browser, the browser will go to the document whose URL is saved on the top of the stack (if the stack is non empty) and will pop the URL from the stack.
If the URL resource can be obtained from the cache, then the browser does so, otherwise a fresh request is made.
Hence even if we disable cache thru response headers, the user can still click back and reload the page from the server. But the current state on the server may not be 'ready' for that request.
There are many strategies that can be used to disable back: Remove the top bar of the browser thru javascript, write a javascript function that will get executed on page load and reset the history stack etc.
On the server side, we can use the "Synchronizer Token pattern"
More on Cookies
Found a few new things about cookies :)
What is the difference between a third-party cookie and a first-party cookie?
If you connect to Web site A and it sets a cookie, that's a first-party cookie. If an ad, embedded within site A is coming from site B, and the ad sets a cookie, that would be a third-party cookie.
What is the difference between persistent and session cookies?
Persistent cookies are cookies that "persist" or reside on your system even after you have closed your browser. Such cookies contain information that can be used to personalize your experience for a particular web site the next time you visit it. Examples would be online community and discussion boards. Unfortunately, such information could also be gathered by hackers and malicious programs and disclose your personal information.
Session cookies are cookies that exist only for a particular "session" or logon. These cookies are deleted automatically the moment you close your browser or choose logout/exit from the web site. Examples would be online banking services. Such cookies are usually safe as they are automatically deleted from your system the moment you exit from the sites.
Persistent and session cookies differ as their life span and lifetime are different.
What is the difference between a third-party cookie and a first-party cookie?
If you connect to Web site A and it sets a cookie, that's a first-party cookie. If an ad, embedded within site A is coming from site B, and the ad sets a cookie, that would be a third-party cookie.
What is the difference between persistent and session cookies?
Persistent cookies are cookies that "persist" or reside on your system even after you have closed your browser. Such cookies contain information that can be used to personalize your experience for a particular web site the next time you visit it. Examples would be online community and discussion boards. Unfortunately, such information could also be gathered by hackers and malicious programs and disclose your personal information.
Session cookies are cookies that exist only for a particular "session" or logon. These cookies are deleted automatically the moment you close your browser or choose logout/exit from the web site. Examples would be online banking services. Such cookies are usually safe as they are automatically deleted from your system the moment you exit from the sites.
Persistent and session cookies differ as their life span and lifetime are different.
Wednesday, June 28, 2006
Spring Vs EJB
In quite a few design brainstorming sessions, the debate between Spring and EJB results in a deadlock. There are developers who are damn passionate about Spring and hate EJBs. Let’s have a look at the main important differences between the two:
1) Distributed Computing – If components in your web-container need to access remote components, then EJB provides in-build support for remote method calls. The EJB container manages all RMI-IIOP connections. Spring provides support for proxying remote calls via RMI, JAX-RPC etc.
2) Transaction Support – EJB by default uses the JTA manager provided by the EJB container and hence can support XA or distributed transactions. Spring does not have default support for distributed transactions, but it can plug in a JTA Transaction manager. Both EJB and Spring allows for declarative transaction demarcation. EJB uses deployment descriptor and Spring uses AOP.
3) Persistance – Entity Beans provide CMP and BMP strategies, but my personal experience with these options has been devastating. Entity Beans are too slow!!!..They just suck..
Spring integrates with Hibernate, IBatis and also has good JDBC wrapper components (JdbcTemplate).
4) Security – EJB provides support for declarative security through the deployment descriptor. But again, this incurs a heavy performance penalty and I have rarely seen projects using EJB-container managed security.
1) Distributed Computing – If components in your web-container need to access remote components, then EJB provides in-build support for remote method calls. The EJB container manages all RMI-IIOP connections. Spring provides support for proxying remote calls via RMI, JAX-RPC etc.
2) Transaction Support – EJB by default uses the JTA manager provided by the EJB container and hence can support XA or distributed transactions. Spring does not have default support for distributed transactions, but it can plug in a JTA Transaction manager. Both EJB and Spring allows for declarative transaction demarcation. EJB uses deployment descriptor and Spring uses AOP.
3) Persistance – Entity Beans provide CMP and BMP strategies, but my personal experience with these options has been devastating. Entity Beans are too slow!!!..They just suck..
Spring integrates with Hibernate, IBatis and also has good JDBC wrapper components (JdbcTemplate).
4) Security – EJB provides support for declarative security through the deployment descriptor. But again, this incurs a heavy performance penalty and I have rarely seen projects using EJB-container managed security.
DAO access in Struts Action?
In quite a few projects in the past, I have directly accessed the DAO methods from the Struts Action classes. This strategy makes a lot of sense when we are only retrieving data from the database and populating beans that would be binded to the JSP page.
But there are many who consider including any persistance code or business logic code in the Action classes as 'sacrilege'. Many prefer having a business service layer (aka business delegate) layer that encapsulates all persistance and business-logic.
But for simple CRUD operations, the service layer just becomes a thin layer around the DAO layer. But nevertheless, there are advantages of adding this business service layer.
But there are many who consider including any persistance code or business logic code in the Action classes as 'sacrilege'. Many prefer having a business service layer (aka business delegate) layer that encapsulates all persistance and business-logic.
But for simple CRUD operations, the service layer just becomes a thin layer around the DAO layer. But nevertheless, there are advantages of adding this business service layer.
- Consolidates the data access layer to all clients. Every method in the DAO need not be present in the ServiceLayer. You see only the methods that we wish to expose to the rest of the world.
- Serves as an attachment point for other services, such as transaction support. For e.g. using Spring.
- Presents a single common interface for other applications to use. For e.g. exposing the business functionality as a WebService.
Another reason this extra layer can be helpful is in a real-life scenario- For e.g. A more complex application there are often other business operations you might want to perform besides just calling you DAO. For example, maybe when an "update" is done you need to call some process that sends out an e-mail or some kind of notification. If you don't use a Service class you are stuck now between coding this business logic either in your Action class or in the DAO. Neither of those places is really a good place for that kind of logic - hence we provide an extra service class to handle business rules that shouldn't be in the Action and don't belong in a DAO. Of course for rapid development, you could possibly skip the Service classes and just use the DAOs directly within your Action.
But there is no absolute right or wrong answer. This reminds me of a quote:
"I'm always wary of absolutes. Know the rules, know the reasons behind the rules, know when and why to break the rules, proceed accordingly."
Friday, June 23, 2006
Struts - Forward Action Vs Direct JSP call
A recent developer asked me why should one use ForwardAction, when one can directly give a link to a separate JSP directly.
The reason is: When we use ForwardAction, the ActionServlet in Struts intercepts the request and provides appropriate attributes such as Message Resource Bundles and also FormBeans.
If we directly give a reference to a JSP page, then the behavior of the Struts tags may become unpredictable.
Another reason when ForwardAction would be necessary is when direct access to JSP files are prevented from direct access by using the "security-constraint" tag in web.xml.
The reason is: When we use ForwardAction, the ActionServlet in Struts intercepts the request and provides appropriate attributes such as Message Resource Bundles and also FormBeans.
If we directly give a reference to a JSP page, then the behavior of the Struts tags may become unpredictable.
Another reason when ForwardAction would be necessary is when direct access to JSP files are prevented from direct access by using the "security-constraint" tag in web.xml.
Monday, June 19, 2006
Deployment options in Tomcat 5.0
Generally developers are used to deploy J2EE applications by dropping the war file or the application folder directly into the webapps directory of Tomcat.
But it is possible for the application to be deployed in a separate location also - even on a separate logical drive.
We just have to create a XML fragment file and place it in the following folder:
$CATALINA_HOME/conf/[enginename]/[hostname]/[applicationName].xml
If one opens this folder, then we can see the context XML descriptors of all applications deployed on Tomcat.
The files typically contain the docBase attribute that points to the physical location on the hard-disk and the web logical path.
<context path="/ASGPortal" docbase="ASGPortal">
So, if want to deploy the above webapp on a separate path, say d:/myApps/ASGPortal, I copy my webapp folder there and change the docBase attribute in Context. Zimple...... :)
Note: This comes really handy when we are using a Source-control tool and the check-in/check-out folders are not under Tomcat.
But it is possible for the application to be deployed in a separate location also - even on a separate logical drive.
We just have to create a XML fragment file and place it in the following folder:
$CATALINA_HOME/conf/[enginename]/[hostname]/[applicationName].xml
If one opens this folder, then we can see the context XML descriptors of all applications deployed on Tomcat.
The files typically contain the docBase attribute that points to the physical location on the hard-disk and the web logical path.
<context path="/ASGPortal" docbase="ASGPortal">
So, if want to deploy the above webapp on a separate path, say d:/myApps/ASGPortal, I copy my webapp folder there and change the docBase attribute in Context. Zimple...... :)
Note: This comes really handy when we are using a Source-control tool and the check-in/check-out folders are not under Tomcat.
Diff btw MTS and COM+
During the good old days of WinNT, MTS used to provide the middle layer for distributed computing using MS technologies. The MTS (Microsoft Transaction Service) environment used to sit in between the client and database and provide distributed transaction services, object pooling, security and other services.
With Windows 2000, MTS was upgraded to COM+. While MTS was actually an add-on to Windows NT, COM+ was natively supported by Windows 2000. This simplified the programming model quite a bit. It was often said that MTS + COM = COM+.
Thus MTS/COM+ is the equivalent of EJB in the J2EE world.
In .NET, COM+ components can be written as .NET component services. The "System.EnterpriseServices" namespace provides us with classes that enable us to deploy a .NET component as a COM+ component. Existing COM+ components can be accessed using .NET remoting and COM-Interop.
With Windows 2000, MTS was upgraded to COM+. While MTS was actually an add-on to Windows NT, COM+ was natively supported by Windows 2000. This simplified the programming model quite a bit. It was often said that MTS + COM = COM+.
Thus MTS/COM+ is the equivalent of EJB in the J2EE world.
In .NET, COM+ components can be written as .NET component services. The "System.EnterpriseServices" namespace provides us with classes that enable us to deploy a .NET component as a COM+ component. Existing COM+ components can be accessed using .NET remoting and COM-Interop.
Friday, June 16, 2006
OnBlur Javascript recursive loop
Recently some of the developers in my team were struggling with a javascript issue.
The problem was very simple. There were 2 textfields on the screen - one after the other. Both of which have an OnBlur call to a routine that simply validates that the fields are not left blank.
Now when the first field is left blank and a 'tab' is pressed, then the javascript goes into a recursive loop !!! The loop is started because we used the focus method in the javascript function: tabbing out of field one fires onblur and sets focus to field two. The function focusses back to field one, "taking focus off field two", which fires a new onblur, which makes your function put focus back on field two firing onblur for field one. This goes on forever.
The solution to this is very simple - Just keep a global variable that points to the current object being validated and check that inside the function. Here is the script for doing so:
var currentObjectName='';
function NoBlank(object, label)
{
if (currentObjectName!=''; currentObjectName!= object.name) return;
currentObjectName=object.name;
if (object.value == "")
{
lc_name = label;
alert(lc_name + " input field cannot be blank!")
object.focus();
return false;
}
currentObjectName='';
return true;
}
The problem was very simple. There were 2 textfields on the screen - one after the other. Both of which have an OnBlur call to a routine that simply validates that the fields are not left blank.
Now when the first field is left blank and a 'tab' is pressed, then the javascript goes into a recursive loop !!! The loop is started because we used the focus method in the javascript function: tabbing out of field one fires onblur and sets focus to field two. The function focusses back to field one, "taking focus off field two", which fires a new onblur, which makes your function put focus back on field two firing onblur for field one. This goes on forever.
The solution to this is very simple - Just keep a global variable that points to the current object being validated and check that inside the function. Here is the script for doing so:
var currentObjectName='';
function NoBlank(object, label)
{
if (currentObjectName!=''; currentObjectName!= object.name) return;
currentObjectName=object.name;
if (object.value == "")
{
lc_name = label;
alert(lc_name + " input field cannot be blank!")
object.focus();
return false;
}
currentObjectName='';
return true;
}
Thursday, June 15, 2006
Automatic Language Identification from text.
In one of my recent projects, there was a business requirement to identify the language of a text document automatically and segregate them.
I tried to do some research on the internet and came up with some open-source tools that can help in identifying a language. One such popular tool is "Lingua" - open source and written in Pearl.
Language identification happens by searching for common patterns of that language. Those patterns can be prefixes, suffixes, common words, ngrams or even sequences of words. More information about n-grams can be found here.
Other interesting links on the same subject:
http://staff.science.uva.nl/~jvgemert/mia_page/LangTools.html
http://odur.let.rug.nl/~vannoord/TextCat/Demo/
http://staff.science.uva.nl/~jvgemert/mia_page/demo.html#Lid
I tried to do some research on the internet and came up with some open-source tools that can help in identifying a language. One such popular tool is "Lingua" - open source and written in Pearl.
Language identification happens by searching for common patterns of that language. Those patterns can be prefixes, suffixes, common words, ngrams or even sequences of words. More information about n-grams can be found here.
Other interesting links on the same subject:
http://staff.science.uva.nl/~jvgemert/mia_page/LangTools.html
http://odur.let.rug.nl/~vannoord/TextCat/Demo/
http://staff.science.uva.nl/~jvgemert/mia_page/demo.html#Lid
Thursday, June 08, 2006
Association - Aggregation and Composition
An aggregation is a special form of association between classes that represents the concept of "WHOLE -PART". Each object of one of the classes that belong to the aggregation (the composed class) is composed of objects of the other class of the aggregation (the component class). The composed class is often called "whole" andthe component classes are often called "parts".
A simple aggregation is an aggregation where each part can be part of more than one whole.
Composition is a special kind of aggregation in which the parts are physically linked to the whole. So, a composition defines restrictions with regard the aggregation concept:
- A part can not simultaneously belong to more than one whole.
- Once a part has been created it lives and dies with its whole.
A simple aggregation is an aggregation where each part can be part of more than one whole.
Composition is a special kind of aggregation in which the parts are physically linked to the whole. So, a composition defines restrictions with regard the aggregation concept:
- A part can not simultaneously belong to more than one whole.
- Once a part has been created it lives and dies with its whole.
Wednesday, June 07, 2006
XMI-XML Metadata Interchange
Recently, I started using Rational Software Modeller for UML modelling. The UML diagram files that the tool creates have a *.emx extension. I was expecting it to be some proprietary binary format, but when I opened the file in Notepad, I was suprised to see a XML format!!!. It looks like even IBM has decided to make its UML models XMI compatible.So what exactly is XMI?
The XML Metadata Interchange (XMI) is an OMG standard for exchanging metadata information via Extensible Markup Language (XML). It can be used for any metadata whose metamodel can be expressed in Meta-Object Facility (MOF). The most common use of XMI is as an interchange format for UML models, although it can also be used for serialization of models of other languages (metamodels).
Here's an excerpt from Wikipedia : http://en.wikipedia.org/wiki/XMI
XMI can be used to transfer UML diagrams between various modeling tools.At the moment there are severe incompatibilities between different modeling tool vendor implementations of XMI, even between interchange of abstract model data. The usage of Diagram Interchange is almost nonexistent. Unfortunately this means exchanging files between UML modeling tools using XMI is rarely possible.
The XML Metadata Interchange (XMI) is an OMG standard for exchanging metadata information via Extensible Markup Language (XML). It can be used for any metadata whose metamodel can be expressed in Meta-Object Facility (MOF). The most common use of XMI is as an interchange format for UML models, although it can also be used for serialization of models of other languages (metamodels).
Here's an excerpt from Wikipedia : http://en.wikipedia.org/wiki/XMI
XMI can be used to transfer UML diagrams between various modeling tools.At the moment there are severe incompatibilities between different modeling tool vendor implementations of XMI, even between interchange of abstract model data. The usage of Diagram Interchange is almost nonexistent. Unfortunately this means exchanging files between UML modeling tools using XMI is rarely possible.
Tuesday, April 18, 2006
Storing passwords in database
This is one of the most common and trivial challenges that developers face in any enterprise application development – How to store passwords in database in a safe and secure manner?
It’s common sense to reconcile that passwords should not be stored as plain text as it would be possible for anyone to hack the passwords if he has access to the database table.
One option is to encrypt the passwords using a symmetric key and decrypting it for comparison during password authentication. But then we have the problem of securely storing the secret symmetric key, because if the key were compromised all the passwords would become accessible.
The most common and simple solution to this problem is to ‘hash’ the passwords before storing it in database. MD5 or SHA-1 hash algorithms can be used to perform a one-way hash of the password. To compare passwords for authentication, you retrieve the password entered by the user and hash it; then you compare the hashed value with the hashed value in the database. This method is quite foolproof and safe as it’s impossible to convert a hashed entry into its original value.
But still it possible for a hacker to perform a brute-force dictionary attack on the passwords and guess some passwords. More info on this here.
To hinder the risk of a dictionary attack, it is important that password contain special characters that are difficult to guess. Another option is to ‘salt’ the password before hashing it. Salting the password means adding some padding data in front or back of the password to create a new string that is hashed and put inside the database table. This padding data could be a random generated number or the userID of the user itself. This makes the dictionary attack much difficult to succeed.
Recently there was a lot of furor over the security of MD5 algorithm. The problem is that of MD5 hash collisions. The problem that arises is the following:
Since what we did is take the characters in some text, however many they are, and producing 128 characters out of them somehow, there will be lots of texts that give the same set of 128 characters, and hence have the same MD5 value. I.e. the hash-function is not 1-1 as we say. So how do we know that the file we received is not one of those other millions of files that have the same MD5 value? The simple answer is, we don’t. But what we believe is that the chance that this other file will be meaningful is miniscule. In other words, we believe that even if someone were to tamper with our file on its way to us, they would not be able to produce a file that has the same MD5 value and can harm u.
But the site below shows how two different postscript files end up having the same MD5 hash. http://www.cits.rub.de/MD5Collisions/
So, what are the other options? Tiger and SHA-2 are still considered to be safe hash functions to use. One could possibly also apply a number of hash-functions to the same file, as secondary checks.
It’s common sense to reconcile that passwords should not be stored as plain text as it would be possible for anyone to hack the passwords if he has access to the database table.
One option is to encrypt the passwords using a symmetric key and decrypting it for comparison during password authentication. But then we have the problem of securely storing the secret symmetric key, because if the key were compromised all the passwords would become accessible.
The most common and simple solution to this problem is to ‘hash’ the passwords before storing it in database. MD5 or SHA-1 hash algorithms can be used to perform a one-way hash of the password. To compare passwords for authentication, you retrieve the password entered by the user and hash it; then you compare the hashed value with the hashed value in the database. This method is quite foolproof and safe as it’s impossible to convert a hashed entry into its original value.
But still it possible for a hacker to perform a brute-force dictionary attack on the passwords and guess some passwords. More info on this here.
To hinder the risk of a dictionary attack, it is important that password contain special characters that are difficult to guess. Another option is to ‘salt’ the password before hashing it. Salting the password means adding some padding data in front or back of the password to create a new string that is hashed and put inside the database table. This padding data could be a random generated number or the userID of the user itself. This makes the dictionary attack much difficult to succeed.
Recently there was a lot of furor over the security of MD5 algorithm. The problem is that of MD5 hash collisions. The problem that arises is the following:
Since what we did is take the characters in some text, however many they are, and producing 128 characters out of them somehow, there will be lots of texts that give the same set of 128 characters, and hence have the same MD5 value. I.e. the hash-function is not 1-1 as we say. So how do we know that the file we received is not one of those other millions of files that have the same MD5 value? The simple answer is, we don’t. But what we believe is that the chance that this other file will be meaningful is miniscule. In other words, we believe that even if someone were to tamper with our file on its way to us, they would not be able to produce a file that has the same MD5 value and can harm u.
But the site below shows how two different postscript files end up having the same MD5 hash. http://www.cits.rub.de/MD5Collisions/
So, what are the other options? Tiger and SHA-2 are still considered to be safe hash functions to use. One could possibly also apply a number of hash-functions to the same file, as secondary checks.
Monday, April 10, 2006
Uses of Reverse Proxy
We are all aware of proxy servers, that enable us to access the internet from inside a firewall. These proxies are known as forward proxies. Similarly we have reverse proxy that sits in front of a webserver and can provide caching and also redirection.
Recently, we needed to expose a website to the internet. I thought the only way of doing it would be to assign a new IP to the webserver machine and have a DNS setup for it. Alternatively, we can put in one more NIC card and have that IP address exposed to the public.
But Reverse Proxy presents us with an interesting alternative. A reverse proxy can be used to enable controlled access from the Web at large to servers behind a firewall.
Here is a simple example provided at the Apache website (Apache can also be used as a reverse proxy server)
Scenario:
Company example.com has a website at www.example.com, which has a public IP address and DNS entry can be accessed from anywhere on the Internet.
The company also has a couple of application servers which have private IP addresses and unregistered DNS entries, and are inside the firewall. The application servers are visible within the network - including the webserver, as "internal1.example.com" and "internal2.example.com", But because they have no public DNS entries, anyone looking at internal1.example.com from outside the company network will get a "no such host" error.
A decision is taken to enable Web access to the application servers. But they should not be exposed to the Internet directly, instead they should be integrated with the webserver, so that http://www.example.com/app1/any-path-here is mapped internally to http://internal1.example.com/any-path-here and http://www.example.com/app2/other-path-here is mapped internally to http://internal2.example.com/other-path-here. This is a typical reverse-proxy situation.
--------------------------------------------------
In my scenario, my network admin guys were able to put my website on the internet without touching my server even once :)
For more information on reverse proxy check out the following links:
http://www.apacheweek.com/features/reverseproxies
http://www.informit.com/articles/article.asp?p=169534&rl=1
http://en.wikipedia.org/wiki/Reverse_proxy
Recently, we needed to expose a website to the internet. I thought the only way of doing it would be to assign a new IP to the webserver machine and have a DNS setup for it. Alternatively, we can put in one more NIC card and have that IP address exposed to the public.
But Reverse Proxy presents us with an interesting alternative. A reverse proxy can be used to enable controlled access from the Web at large to servers behind a firewall.
Here is a simple example provided at the Apache website (Apache can also be used as a reverse proxy server)
Scenario:
Company example.com has a website at www.example.com, which has a public IP address and DNS entry can be accessed from anywhere on the Internet.
The company also has a couple of application servers which have private IP addresses and unregistered DNS entries, and are inside the firewall. The application servers are visible within the network - including the webserver, as "internal1.example.com" and "internal2.example.com", But because they have no public DNS entries, anyone looking at internal1.example.com from outside the company network will get a "no such host" error.
A decision is taken to enable Web access to the application servers. But they should not be exposed to the Internet directly, instead they should be integrated with the webserver, so that http://www.example.com/app1/any-path-here is mapped internally to http://internal1.example.com/any-path-here and http://www.example.com/app2/other-path-here is mapped internally to http://internal2.example.com/other-path-here. This is a typical reverse-proxy situation.
--------------------------------------------------
In my scenario, my network admin guys were able to put my website on the internet without touching my server even once :)
For more information on reverse proxy check out the following links:
http://www.apacheweek.com/features/reverseproxies
http://www.informit.com/articles/article.asp?p=169534&rl=1
http://en.wikipedia.org/wiki/Reverse_proxy
Thursday, April 06, 2006
Unix Quirks for Windows developers
Recently came across a wonderful blog stating a few things about Unix/Linux which ever developer should know. The link to the blog is here.
Some useful points in the blog were:
Some useful points in the blog were:
- In Unix, if U want Ur application or server to use a port less than 1024, then U must be running as 'root'. This imposes security risks !!!
- In Unix, it is possible for one process to open a file stream and an another process to delete the same file. (Windows does a automatic file lock). For the same reason, in Unix, U can delete a directory right from under it.
- Equivalent of Windows services in the Unix world are just plain shell scripts that are mentioned in the /etc/init.d directory.
- The Unix shell runs scripts by creating a copy of itself and running the script in the new shell. This new shell will read in the script, perform all the steps in the script (e.g. set all the environment variables) and then exit, leaving the original shell and its environment unchanged. So to run scripts in the same shell, we need to type ". setenv.sh" For c-shell, we need to type "source setenv.sh"
- And last, but not the least, every developer learns early - Unix new line character is \n and on Windows \r\n.
Saturday, April 01, 2006
Debugging JavaScript
While working with VisualStudio.NET, I was impressed with the ability of VS.NET to even debug JavaScript on a HTML page. It saved a lot of time - or the other alternative was writting alert() statements.
I wondered if there was some similar JavaScript Debugger tool for the Java community.
Fortunately, Mozilla has come up with a cool tool that allows developers to debug Javascript code. The tool is "Venkman Debugger" and it's a free download.
Here's the URL for more details: http://www.mozilla.org/projects/venkman/
For firefox 1.0 (my fav browser), the debugger is available as a plug-in. Installation was a breeze !!!
I just had to download the *.xpi" file and drag and drop the file in a open window of Firefox...that's it..Then start the debugger from the tools menu...
After this, any page U see on Firefox - the debugger windows will show all the Javascript functions and we can set breakpoint and step thru the code...also available is the local window and watch window :)
Happy debugging..
I wondered if there was some similar JavaScript Debugger tool for the Java community.
Fortunately, Mozilla has come up with a cool tool that allows developers to debug Javascript code. The tool is "Venkman Debugger" and it's a free download.
Here's the URL for more details: http://www.mozilla.org/projects/venkman/
For firefox 1.0 (my fav browser), the debugger is available as a plug-in. Installation was a breeze !!!
I just had to download the *.xpi" file and drag and drop the file in a open window of Firefox...that's it..Then start the debugger from the tools menu...
After this, any page U see on Firefox - the debugger windows will show all the Javascript functions and we can set breakpoint and step thru the code...also available is the local window and watch window :)
Happy debugging..
Friday, March 31, 2006
Diff btw div and span tags in HTML
I was trying to get the hang of AJAX and was learning a lot of JavaScript and HTML. I was confused btw the <div>and <span> tags in HTML. A quick google came up with these answers:
The main difference between <div> and <span>is that <div>defaults as a block-level element and <span>defaults as an inline element.
Block-level elements create a new formatting context. They are stacked vertically(acts as a paragraph break) in the order they appear in the source code and may contain any number of other block-level elements or inline elements.
Inline elements do not create a new formatting context. They line up horizontally within their block container in the order they appear in the source code, wrapping to new lines within their block container if necessary and can contain only other inline level elements (or inline text boxes).
Both <div> and <span>are generic elements. Both can be used as many times as you like on a page. They hold no defaults settings besides their value for display (block on <div>, inline on <span>)
The main difference between <div> and <span>is that <div>defaults as a block-level element and <span>defaults as an inline element.
Block-level elements create a new formatting context. They are stacked vertically(acts as a paragraph break) in the order they appear in the source code and may contain any number of other block-level elements or inline elements.
Inline elements do not create a new formatting context. They line up horizontally within their block container in the order they appear in the source code, wrapping to new lines within their block container if necessary and can contain only other inline level elements (or inline text boxes).
Both <div> and <span>are generic elements. Both can be used as many times as you like on a page. They hold no defaults settings besides their value for display (block on <div>, inline on <span>)
Friday, March 24, 2006
Debugging Server-side Java with JPDA
JPDA stands for Java Platform Debugger Architecture. It is a new debugging design adopted by the VM that facilitates debuggers to attach to the VM process easily. More info about JPDA can be found here.
I tried out debugging a Struts application running on Tomcat using Eclipse. (Versions: Tomcat-5.0; Eclipse-3.1.2)
Here are the steps to be followed:
I tried out debugging a Struts application running on Tomcat using Eclipse. (Versions: Tomcat-5.0; Eclipse-3.1.2)
Here are the steps to be followed:
- Start Tomcat in JPDA debug mode. For this, set up two variables in the environment as follows:
- The first variable is: set JPDA_TRANSPORT=dt_socket (This tells the VM that the debugger would talk to the VM on Tcp sockets)
- The second variable is: set JPDA_ADDRESS=8000 (This tells the VM the port on which it should listen for debugger connections)
- Go to the command prompt and run the 'Catalina.bat' batch file present in {TomcatHome}\bin. On the command prompt pass the following argument: catalina jdpa start
- Go to Eclipse and open the Debug window. Create a new configuration under 'Remote Java Application' . Make sure 'Connection Type' is Socket and port is 8000
- Navigate the webapplication thru web browser and see Ur Eclipse stop at breakpoints..
Happy debugging............
Precompiling JSPs in Tomcat
For faster startup access to a website, it is sometimes desirable to precompile all the JSP pages on a production server, so that the first users of the website do not have to bear the performance hit of JSP compilation (first to servlet java file and then to class file)
Tomcat 5.0 and above comes with a cool ANT script that uses the Jasper JSP compiler to precompile the JSPs in a webapp. The ANT script is available here.
On running the ANT script, the "WEB-INF\classes" directory has a new package "\org\apache\jsp" that contains all the class files of the compiled JSPs. The src folder would contain the generated Java Servlet files.
If U edit a JSP page on the fly, then it would again be compiled at run-time and swapped in memory with the old one, but the classes directory would still contain the old class file.
Tomcat 5.0 and above comes with a cool ANT script that uses the Jasper JSP compiler to precompile the JSPs in a webapp. The ANT script is available here.
On running the ANT script, the "WEB-INF\classes" directory has a new package "\org\apache\jsp" that contains all the class files of the compiled JSPs. The src folder would contain the generated Java Servlet files.
If U edit a JSP page on the fly, then it would again be compiled at run-time and swapped in memory with the old one, but the classes directory would still contain the old class file.
Monday, March 20, 2006
StringBuffer Myth
I have noticed that a lot of people are wasting their precious time changing code that contains "+" overloaded String operator toStringBuffer...in the following way :
For eg.
-----------------
1 ) String sTemp = "a" + "b" + "c";is being replaced with
---------------
2 )StringBuffer sBuffer = new StringBuffer()
sBuffer.append("a");
sBuffer.append("b");
sBuffer.append("c");
String sTemp = sBuffer.toString();
Now the point is for simple string concatenations such as the above the compiler itself does the conversion to StringBuffer. Thus the code in 1) gets converted to code in 2) during compilation time only.......ie conversion to platform independant byte form...
So there is no need for us to do this explictly....But yes, there will be a remarkable advantage when we have String concatenation in a for loop...
for eg, if the above code was within a for loop.....for eg:
for(int i=0;i<n;i++)
{ sTemp = "a" + "b" + "c";}
Then it makes sense to use StringBuffer, otherwise a new String Buffer object will be created for each iteration of the loop. So in such cases we can instantiate the StringBuffer outside the loop and just use "append" inside the loop..
For eg.
-----------------
1 ) String sTemp = "a" + "b" + "c";is being replaced with
---------------
2 )StringBuffer sBuffer = new StringBuffer()
sBuffer.append("a");
sBuffer.append("b");
sBuffer.append("c");
String sTemp = sBuffer.toString();
Now the point is for simple string concatenations such as the above the compiler itself does the conversion to StringBuffer. Thus the code in 1) gets converted to code in 2) during compilation time only.......ie conversion to platform independant byte form...
So there is no need for us to do this explictly....But yes, there will be a remarkable advantage when we have String concatenation in a for loop...
for eg, if the above code was within a for loop.....for eg:
for(int i=0;i<n;i++)
{ sTemp = "a" + "b" + "c";}
Then it makes sense to use StringBuffer, otherwise a new String Buffer object will be created for each iteration of the loop. So in such cases we can instantiate the StringBuffer outside the loop and just use "append" inside the loop..
Retrieval of AutoGenerated Keys
We often face the problem of retrieving a 'auto-generated' column after a 'INSERT' operation. For e.g.
insert into myTable (name) values ('Naren')");
Now immediately after the insert, I want to get the 'auto-generated' key of the inserted row. The only way to do it earlier in JDBC was to fire another query to get the last inserted row. But this method is fundamentally flawed, as there could be other inserts that have happened in-between.
Now, in JDBC 3.0 (in JDK 1.4), we have core JDBC methods that enable us to retrive the autogenerated key automatically. For e.g.
int rowcount = stmt.executeUpdate("sql here...",Statement.RETURN_GENERATED_KEYS);
ResultSet rs = stmt.getGeneratedKeys ();
The ability to retrieve auto generated keys provides flexibility to the JDBC programmer and it provides a mechanism to realize performance boosts when accessing data.
The following methods are available since JDK 1.4
public int executeUpdate(String sql, int autoGeneratedKeys) throws SQLException
Executes the given SQL statement and signals the driver with the given flag about whether the auto-generated keys produced by this Statement object should be made available for retrieval.
Parameters:
sql - must be an SQL INSERT, UPDATE or DELETE statement or an SQL statement that returns nothing.
autoGeneratedKeys - a flag indicating whether auto-generated keys should be made available for retrieval; one of the following constants: Statement.RETURN_GENERATED_KEYS
Statement.NO_GENERATED_KEYS
---------------------------------------
public int executeUpdate(String sql, int[] columnIndexes)
throws SQLExceptionExecutes the given SQL statement and signals the driver that
the auto-generated keys indicated in the given array should be made available for retrieval. The driver will ignore the array if the SQL statement is not an INSERT statement.
Parameters:
columnIndexes - an array of column indexes indicating the columns that should be returned from the inserted row
------------------------------------------
public int executeUpdate(String sql, String[] columnNames)
throws SQLExceptionExecutes the given SQL statement and signals the driver that
the auto-generated keys indicated in the given array should be made available for retrieval. The driver will ignore the array if the SQL statement is not an INSERT statement.
Parameters:
columnNames - an array of the names of the columns that should be returned from the inserted row
----------------------------------------
In Spring JDBC API, the JDBCTemplate has a utility method that directly gives the genetated key:
int update(PreparedStatementCreator psc, KeyHolder generatedKeyHolder)
insert into myTable (name) values ('Naren')");
Now immediately after the insert, I want to get the 'auto-generated' key of the inserted row. The only way to do it earlier in JDBC was to fire another query to get the last inserted row. But this method is fundamentally flawed, as there could be other inserts that have happened in-between.
Now, in JDBC 3.0 (in JDK 1.4), we have core JDBC methods that enable us to retrive the autogenerated key automatically. For e.g.
int rowcount = stmt.executeUpdate("sql here...",Statement.RETURN_GENERATED_KEYS);
ResultSet rs = stmt.getGeneratedKeys ();
The ability to retrieve auto generated keys provides flexibility to the JDBC programmer and it provides a mechanism to realize performance boosts when accessing data.
The following methods are available since JDK 1.4
public int executeUpdate(String sql, int autoGeneratedKeys) throws SQLException
Executes the given SQL statement and signals the driver with the given flag about whether the auto-generated keys produced by this Statement object should be made available for retrieval.
Parameters:
sql - must be an SQL INSERT, UPDATE or DELETE statement or an SQL statement that returns nothing.
autoGeneratedKeys - a flag indicating whether auto-generated keys should be made available for retrieval; one of the following constants: Statement.RETURN_GENERATED_KEYS
Statement.NO_GENERATED_KEYS
---------------------------------------
public int executeUpdate(String sql, int[] columnIndexes)
throws SQLExceptionExecutes the given SQL statement and signals the driver that
the auto-generated keys indicated in the given array should be made available for retrieval. The driver will ignore the array if the SQL statement is not an INSERT statement.
Parameters:
columnIndexes - an array of column indexes indicating the columns that should be returned from the inserted row
------------------------------------------
public int executeUpdate(String sql, String[] columnNames)
throws SQLExceptionExecutes the given SQL statement and signals the driver that
the auto-generated keys indicated in the given array should be made available for retrieval. The driver will ignore the array if the SQL statement is not an INSERT statement.
Parameters:
columnNames - an array of the names of the columns that should be returned from the inserted row
----------------------------------------
In Spring JDBC API, the JDBCTemplate has a utility method that directly gives the genetated key:
int update(PreparedStatementCreator psc, KeyHolder generatedKeyHolder)
Sunday, March 19, 2006
When to do Object Pooling?
Pooling basically means utilizing your resources better. For example, imagine a fairly large
number of clients utilizing a small number of database or network connections efficiently. By
limiting object access to only the period when the client requires it, you can free resources for
use by other clients. Increasing utilization through pooling usually increases system
performance.
You can use pooling to minimize costly initializations. Typical examples include database and
network connections and threads. Such connections often take a significant amount of time to
initialize. You can achieve significant savings by creating these connections once and reusing
them later. Finally, you can pool objects whose initialization is expensive, in terms of time,
memory, or other resources. For example, most containers pool Enterprise JavaBeans to avoid
repeated resource allocation and state initialization.
Examples of objects holding external OS resources:
-database connection pooling,
- socket connection pooling (including HTTP, RMI, CORBA, WS, etc...)
- thread pooling,
- bitmaps, fonts, other graphics objects...
For objects that do not hold external OS resources, but are time-consuming to initialize and are
memory-heavy, a cost benefit analysis needs to be done. What is the cost of pooling
(synchronization, management, GC etc.) vs the benefit (quick access to connection or socket).One very important concern during pooling is the problem of concurrency bottlenecks....when we snchronize access to the pooled resources.
Simple object pooling (which hold no external resources, but only occupy memory) could be a
waste, as the performance improvments in the latest versions of the JVM have tilted this
equation, so we better re-evaluate what we think we know........There was also an old school of thought that pooling reduces the need of GC and hence improves the performance. But with the introduction of the concept of 'generations' to GC algorithms, it is possible that pooled resources would be more difficult to GC as they are put in older generations of objects.
But for external resources the JVM improvements are of no-concern. Whether objects holding
external resources (out of JVM, either OS resources on JVM host machine, or on the other machine) should be pooled or not, does not depend on JVM efficiency, but on their availability, weight and and other costs of holding these resources.
Why stateless session beans pooled ?The EJB spec states that only one thread at the time can execute method code in a statelss session bean instance. So you need to pool them to provide concurrency. The qustion is whether this spec requirement makes sense?
As only reason for this request I can see is that this way you can have local instance state (as
instance fields) in a stateless session bean that is valid during a single method execution. Note
that your method can call other (possibly private) methods of the same bean, so in this scenario
this makes sense.
However, you can get the same behavior by holding a state and logic in a separate POJO and having your session bean playing a facade to that POJO. Probably this request is to simplify programming model for stateless session EJBs, making them completely thread safe .
The EJB standard does not require that Stateless Session EJBs have no internal state (ie.
fields). It simply requires that no conversational state be maintained between the bean and its
clients. A pool of these that are doled out to client threads on a per-call-basis is valuable if
the bean manages some expensive-to-allocate-or-create resource.
From the EJB 2.0 Specification, section 7.5.6: "A container serializes calls to each session bean instance. Most containers will support many instances of a session bean executing concurrently; however, each instance sees only a serialized sequence of method calls. Therefore, a session bean does not have to be coded as reentrant."
Is there some other reason why stateless session beans are pooled?...Something in the
architecture of EJB that forces this decision?
number of clients utilizing a small number of database or network connections efficiently. By
limiting object access to only the period when the client requires it, you can free resources for
use by other clients. Increasing utilization through pooling usually increases system
performance.
You can use pooling to minimize costly initializations. Typical examples include database and
network connections and threads. Such connections often take a significant amount of time to
initialize. You can achieve significant savings by creating these connections once and reusing
them later. Finally, you can pool objects whose initialization is expensive, in terms of time,
memory, or other resources. For example, most containers pool Enterprise JavaBeans to avoid
repeated resource allocation and state initialization.
Examples of objects holding external OS resources:
-database connection pooling,
- socket connection pooling (including HTTP, RMI, CORBA, WS, etc...)
- thread pooling,
- bitmaps, fonts, other graphics objects...
For objects that do not hold external OS resources, but are time-consuming to initialize and are
memory-heavy, a cost benefit analysis needs to be done. What is the cost of pooling
(synchronization, management, GC etc.) vs the benefit (quick access to connection or socket).One very important concern during pooling is the problem of concurrency bottlenecks....when we snchronize access to the pooled resources.
Simple object pooling (which hold no external resources, but only occupy memory) could be a
waste, as the performance improvments in the latest versions of the JVM have tilted this
equation, so we better re-evaluate what we think we know........There was also an old school of thought that pooling reduces the need of GC and hence improves the performance. But with the introduction of the concept of 'generations' to GC algorithms, it is possible that pooled resources would be more difficult to GC as they are put in older generations of objects.
But for external resources the JVM improvements are of no-concern. Whether objects holding
external resources (out of JVM, either OS resources on JVM host machine, or on the other machine) should be pooled or not, does not depend on JVM efficiency, but on their availability, weight and and other costs of holding these resources.
Why stateless session beans pooled ?The EJB spec states that only one thread at the time can execute method code in a statelss session bean instance. So you need to pool them to provide concurrency. The qustion is whether this spec requirement makes sense?
As only reason for this request I can see is that this way you can have local instance state (as
instance fields) in a stateless session bean that is valid during a single method execution. Note
that your method can call other (possibly private) methods of the same bean, so in this scenario
this makes sense.
However, you can get the same behavior by holding a state and logic in a separate POJO and having your session bean playing a facade to that POJO. Probably this request is to simplify programming model for stateless session EJBs, making them completely thread safe .
The EJB standard does not require that Stateless Session EJBs have no internal state (ie.
fields). It simply requires that no conversational state be maintained between the bean and its
clients. A pool of these that are doled out to client threads on a per-call-basis is valuable if
the bean manages some expensive-to-allocate-or-create resource.
From the EJB 2.0 Specification, section 7.5.6: "A container serializes calls to each session bean instance. Most containers will support many instances of a session bean executing concurrently; however, each instance sees only a serialized sequence of method calls. Therefore, a session bean does not have to be coded as reentrant."
Is there some other reason why stateless session beans are pooled?...Something in the
architecture of EJB that forces this decision?
Friday, March 03, 2006
HSQL - A cool Java database..
Recently I developed a portal which made use of MySQL database. The database was small in size and had only a few tables. But I was facing problems, when the web-application had to be installed in different locations. I had to give instructions to users on how to create the MySQL database, run the script to add all the necessary tables etc.
Then I came across HSQL (Hypersonic SQL) database. This is a 100% pure Java database and can be run in-process inside a Java application...even a webapplication. No need to install anything or start any database process. More information about HSQL can be found at http://www.hsqldb.org/
For me, just the following 2 lines of code, created a database in my Tomcat webapps directory.
Class.forName("org.hsqldb.jdbcDriver");
Connection c = DriverManager.getConnection("jdbc:hsqldb:file:webapps/myPortal/database/narenDB", "sa", "");
So simple.........:)
Then I came across HSQL (Hypersonic SQL) database. This is a 100% pure Java database and can be run in-process inside a Java application...even a webapplication. No need to install anything or start any database process. More information about HSQL can be found at http://www.hsqldb.org/
For me, just the following 2 lines of code, created a database in my Tomcat webapps directory.
Class.forName("org.hsqldb.jdbcDriver");
Connection c = DriverManager.getConnection("jdbc:hsqldb:file:webapps/myPortal/database/narenDB", "sa", "");
So simple.........:)
Thursday, March 02, 2006
Free Portal frameworks out there
Recently I was trying to evaluate some open-source portals that I can use for my personal use.
Here is the list of interesting portals I found out:
http://www.exoplatform.com/
http://www.liferay.com/
http://portals.apache.org/
http://jboss.com/products/jbossportal
http://www.gridsphere.org/
Out of the above I found Apache Jetspeed 2.0 and Liferay to be promising...I had a bad experience with JBoss Portal...it sucks !!!
Here is the list of interesting portals I found out:
http://www.exoplatform.com/
http://www.liferay.com/
http://portals.apache.org/
http://jboss.com/products/jbossportal
http://www.gridsphere.org/
Out of the above I found Apache Jetspeed 2.0 and Liferay to be promising...I had a bad experience with JBoss Portal...it sucks !!!
Wednesday, March 01, 2006
What is virtual hosting?
Virtual hosting is essentially "shared web hosting". Virtual hosting is a method that webservers use to host more than one domain name on the same host. It is generally the most economical option for hosting as many people share the overall cost of server maintenance.
There are two basic methods of accomplishing virtual hosting:
name-based, and IP address or ip-based.
In name-based virtual hosting, also called shared IP hosting, the virtual hosts serve multiple host names on a single machine with a single IP address.
With web browsers that support HTTP/1.1 (as almost all do today), upon connecting to a webserver, the browser sends the URL to the server. The server can use this information to determine which web site to show the user. So each website would have a DNS entry and all the DNS entries for the websites point to the same IP address.
In IP-based virtual hosting, also called dedicated IP hosting, each webserver has a different IP address. The webserver is configured with multiple physical network interfaces, or virtual network interfaces on the same physical interface. The webserver uses the IP address from the HTTP request to determine which web site to show the user.
Disadvantages of virtual hosting:
Older web browsers that only support HTTP/1.0 will not work because they do not send the URL.
If the Domain Name System (DNS) is not properly functioning, it becomes much harder to access a virtually-hosted website.
They do not support secure websites (HTTPS), at least not on the same TCP port. All virtual hosts on a single HTTPS webserver must share the same digital certificate. Because the SSL handshake takes place before the expected hostname is sent to the server, the server doesn't know which encryption key to use when the connection is made.
There are two basic methods of accomplishing virtual hosting:
name-based, and IP address or ip-based.
In name-based virtual hosting, also called shared IP hosting, the virtual hosts serve multiple host names on a single machine with a single IP address.
With web browsers that support HTTP/1.1 (as almost all do today), upon connecting to a webserver, the browser sends the URL to the server. The server can use this information to determine which web site to show the user. So each website would have a DNS entry and all the DNS entries for the websites point to the same IP address.
In IP-based virtual hosting, also called dedicated IP hosting, each webserver has a different IP address. The webserver is configured with multiple physical network interfaces, or virtual network interfaces on the same physical interface. The webserver uses the IP address from the HTTP request to determine which web site to show the user.
Disadvantages of virtual hosting:
Older web browsers that only support HTTP/1.0 will not work because they do not send the URL.
If the Domain Name System (DNS) is not properly functioning, it becomes much harder to access a virtually-hosted website.
They do not support secure websites (HTTPS), at least not on the same TCP port. All virtual hosts on a single HTTPS webserver must share the same digital certificate. Because the SSL handshake takes place before the expected hostname is sent to the server, the server doesn't know which encryption key to use when the connection is made.
Tuesday, February 28, 2006
MySQL - import and export of database
Recently I had to move my MySQL server from a WinXP machine to a Win2000 server machine. I thought that the data migration of the MySQl database would be a pain.
To my suprise, it just took me 5 mins flat to do it. Here are the steps:
1)First export the database into a flat file. This exports not just the schema but also the "insert" statements for all the data in the tables
mysqldump -u DBUSER -p DBNAME > DBNAME.sql
substituting DBUSER with your MySQL username and DBNAME with your database name.
2) Create a new empty schema/database on your new machine. The name of the database will probably be same as the name in the old server.
3) Import the dump file into the new database server.
mysql -u DBUSER -p -h MACHINE-NAME DBNAME< DBName.sql
substituting DBUSER with your MySQL username and DBNAME with your database name, and MACHINE-NAME with the name of the SQLServer instance - quite often the name of the machine itself.
That's it...migration of database done.
To my suprise, it just took me 5 mins flat to do it. Here are the steps:
1)First export the database into a flat file. This exports not just the schema but also the "insert" statements for all the data in the tables
mysqldump -u DBUSER -p DBNAME > DBNAME.sql
substituting DBUSER with your MySQL username and DBNAME with your database name.
2) Create a new empty schema/database on your new machine. The name of the database will probably be same as the name in the old server.
3) Import the dump file into the new database server.
mysql -u DBUSER -p -h MACHINE-NAME DBNAME< DBName.sql
substituting DBUSER with your MySQL username and DBNAME with your database name, and MACHINE-NAME with the name of the SQLServer instance - quite often the name of the machine itself.
That's it...migration of database done.
Why put a webserver in front of an application server?
A lot of my developer friends pop up the question of why to use a webserver when today's application servers such as Weblogic, Websphere, Tomcat, JBoss etc. also have a HTTP listener. But in almost every architecture, we will see Apache in front of Tomcat, or IBM Http Server in front of WAS. The question is why?...and the answers are as follows:
- Webservers serve static content faster than application servers. Hence for performace reasons, it makes sense to shift all the static contect to the webserver. (J2EE developers hate this, as they now have to split the *.war files)
- The webserver can be put in a DMZ to enable enhanced security.
- The webserver can be used as a load balancer over multiple application server instances.
- The webserver can have agents/plug-in's to security servers such as Netegrity. Hence security is taken care by the webserver, putting less load on the application server.
What is a DMZ?
DMZ stands for demilitarized zone. DMZ is also known as perimeter network and is used for security purposes. A DMZ is that part of the network/subnet that sits between the organisations LAN and the Internet. The concept behind creating a DMZ is that m/c's from the Internet and the org's LAN can connect to DMZ, but the DMZ can only connect to the external network - i.e. the Internet.
This allows m/c's hosted in the DMZ to interact with the external network for services such as Email, Web and DNS. So even if a host in the DMZ is compromised, the internal network is still safe. Connections from the external network to the DMZ are usually controlled using port address translation (PAT).
A DMZ can be created by connecting each network to different ports of a single firewall (3-legged-firewall) or by having 2 firewalls and the area btw them as a DMZ.
In case of Enterprise Applications (3-layered), the webserver is placed in the DMZ. This protects the applications business logic and database from intruder attacks.
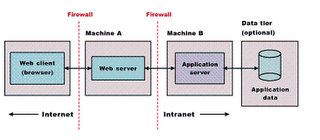
This allows m/c's hosted in the DMZ to interact with the external network for services such as Email, Web and DNS. So even if a host in the DMZ is compromised, the internal network is still safe. Connections from the external network to the DMZ are usually controlled using port address translation (PAT).
A DMZ can be created by connecting each network to different ports of a single firewall (3-legged-firewall) or by having 2 firewalls and the area btw them as a DMZ.
In case of Enterprise Applications (3-layered), the webserver is placed in the DMZ. This protects the applications business logic and database from intruder attacks.

Friday, February 24, 2006
Citrix Server and Terminal Services
I was quite familiar with Terminal Services in Windows and also the Remote Desktop Protocol used in it. But recently I came across a technology called 'Citrix' that was similar in nature, so I decided to dig into the root of it. This is the info I found on the net:
Citrix Presentation ServerSoftware from Citrix that provides a timeshared, multiuser environment for Unix and Windows servers. Formerly MetaFrame, Citrix Presentation Server uses the ICA protocol to turn the client machine into a terminal and governs the input/output between the client and server. Applications can also be run from a Web browser
Citrix Presentation Server (formerly Citrix MetaFrame) is a remote access/application publishing product built on the Independent Computing Architecture (ICA), Citrix Systems' thin client protocol. The Microsoft Remote Desktop Protocol, part of Microsoft's Terminal Services, is based on Citrix technology and was licensed from Citrix in 1997. Unlike traditional framebuffered protocols like VNC, ICA transmits high-level window display information, much like the X11 protocol, as opposed to purely graphical information.
Independent Computing Architecture (ICA) is a proprietary protocol for an application server system, designed by Citrix Systems. The protocol lays down a specification for passing data between server and clients, but is not bound to any one platform.
Practical products conforming to ICA are Citrix's WinFrame and MetaFrame products. These permit ordinary Windows applications to be run on a suitable Windows server, and for any supported client to gain access to those applications. The client platforms need not run Windows, there are clients for Mac and Unix for example.
Citrix Presentation ServerSoftware from Citrix that provides a timeshared, multiuser environment for Unix and Windows servers. Formerly MetaFrame, Citrix Presentation Server uses the ICA protocol to turn the client machine into a terminal and governs the input/output between the client and server. Applications can also be run from a Web browser
Citrix Presentation Server (formerly Citrix MetaFrame) is a remote access/application publishing product built on the Independent Computing Architecture (ICA), Citrix Systems' thin client protocol. The Microsoft Remote Desktop Protocol, part of Microsoft's Terminal Services, is based on Citrix technology and was licensed from Citrix in 1997. Unlike traditional framebuffered protocols like VNC, ICA transmits high-level window display information, much like the X11 protocol, as opposed to purely graphical information.
Independent Computing Architecture (ICA) is a proprietary protocol for an application server system, designed by Citrix Systems. The protocol lays down a specification for passing data between server and clients, but is not bound to any one platform.
Practical products conforming to ICA are Citrix's WinFrame and MetaFrame products. These permit ordinary Windows applications to be run on a suitable Windows server, and for any supported client to gain access to those applications. The client platforms need not run Windows, there are clients for Mac and Unix for example.
Tuesday, January 31, 2006
Tibco RV vs Tibco EMS
A lot of people are familiar with the Tibco RV (Rendezvous) product. This product is around 20 years old and powers many mission critical systems across different domains. Tibco has another product called Tibco EMS (Enterprise messaging Server) which is based on the JMS hub-and-spoke model and is quite popular in EAI. So what's the difference btw the two products? - When to use what ?
First we need to understand the differences in the architecture between the two products. Tibco RV is based on the multicast publish/subscribe model, where as Tibco EMS is based on the hub-and-spoke model.
Multicast is the delivery of information to a group of destinations simultaneously using the most efficient strategy to deliver the messages over each link of the network only once and only create copies when the links to the destinations split. By comparison with multicast, conventional point-to-single-point delivery is called unicast. When unicast is used to deliver to several recipients, a copy of the data is sent from the sender to each recipient, resulting in inefficient and badly scalable duplication at the sending side.
Googled out a white paper that contained some good architecture details about Tibco RV. The link is here.
Excerpt from the article:
TIB/RV is based on a distributed architecture . An installation of TIB/RV resides on each host on the network.Hence it eliminates the bottlenecks and single points offailures could be handled. It allows programs to sendmessages in a reliable, certified and transactional manner,depending on the requirements. Messaging can be delivered in point-to-point or publish/subscribe, synchronously orasynchronously, locally delivered or sent via WAN or theInternet. Rendezvous messages are self-describing and platform independent.
RVD (Rendezvous Daemon) is a background process that sits in between the RVprogram and the network. It is responsible for the deliveryand the acquisition of messages, either in point-to-point or publish/subscribe message domain. It is the most important component of the whole TIB/RV.Theoretically, there is an installation of RVD on every host on the network. However, it is possible to connect to a remote daemon, which sacrifices performance and transparencies. The RV Sender program passes the message and destination topic to RVD. RVD then broadcasts this message using User Data Packet(UDP) to the entire network. All subscribing computers with RVDs on the network will receive this message. RVD will filter the messages which non-subscribers will not be notified of the message. Therefore only subscriber programs to the particular topic will get the messages.
So when to use Tibco RV and when to use Tibco EMS (or any other hub-and-spoke model). An article at http://eaiblueprint.com/3.0/?p=17 describes the trade-offs between the two models:
Excerpt:
In my opinion, the multicast-based publish/subscribe messaging is an excellent solution for near-real-time message dissemination when 1 to 'very-many' delivery capabilities matter. RV originated on the trading floors as a vehicle for disseminating financial information such as stock prices.
However, in most EAI cases the opposite requirements are true:
‘Cardinality’ of message delivery is 1-1, 1-2; 1 to-very-many is a rare case. With exception of ‘consolidated application’ integration model (near real time request reply with timeout heuristics), reliability of message delivery takes priority over performance. Effectively, in most EAI implementations of RV, RV ends up simulating a queueing system using its ‘Certified Delivery’ mechanism. While this works, it is a flawed solution (see the discussion of Certified Messaging below).
Reliable delivery is a ‘native’ function of hub-and-spoke solutions. The multicast solution must be augmented with local persistence mechanism and re-try mechanism.
While RV offers reliable delivery (queueing) referred to as Certified Messaging, this solution is flawed in that: Inherently, reliability of CM is not comparable to the hub-and-spoke topologies as the data is stored in local file systems using non-transactional disk operations, as opposed to centralized database in hub-and-spoke topology. Corruption of RV ‘ledger files’ is not a rare case that leads to loss of data. Temporal de-coupling is not the case. While a message can be queue for a later delivery (in case the target system is unavailable), for a message to be actually delivered both system must be up at the same time.
RV / CM lacks a basic facility of any queueing system: a queue browser that is frequently required for production support (for example, in order to remove an offending message). In contrast, MQ Series offers an out-of the box queue browser and a host of third party solutions. Transactional messaging is difficult to implement in multicast environment. TIBCO offers a transactional augmentation of RV (RVTX) that guarantees a 1-and-onlu-once delivery; however, this solution essentially converts RV into a hub-and-spoke system. Consequently, very few RV implementations are transactional.
Having said that, the shortcomings of hub and spoke include:
First we need to understand the differences in the architecture between the two products. Tibco RV is based on the multicast publish/subscribe model, where as Tibco EMS is based on the hub-and-spoke model.
Multicast is the delivery of information to a group of destinations simultaneously using the most efficient strategy to deliver the messages over each link of the network only once and only create copies when the links to the destinations split. By comparison with multicast, conventional point-to-single-point delivery is called unicast. When unicast is used to deliver to several recipients, a copy of the data is sent from the sender to each recipient, resulting in inefficient and badly scalable duplication at the sending side.
Googled out a white paper that contained some good architecture details about Tibco RV. The link is here.
Excerpt from the article:
TIB/RV is based on a distributed architecture . An installation of TIB/RV resides on each host on the network.Hence it eliminates the bottlenecks and single points offailures could be handled. It allows programs to sendmessages in a reliable, certified and transactional manner,depending on the requirements. Messaging can be delivered in point-to-point or publish/subscribe, synchronously orasynchronously, locally delivered or sent via WAN or theInternet. Rendezvous messages are self-describing and platform independent.
RVD (Rendezvous Daemon) is a background process that sits in between the RVprogram and the network. It is responsible for the deliveryand the acquisition of messages, either in point-to-point or publish/subscribe message domain. It is the most important component of the whole TIB/RV.Theoretically, there is an installation of RVD on every host on the network. However, it is possible to connect to a remote daemon, which sacrifices performance and transparencies. The RV Sender program passes the message and destination topic to RVD. RVD then broadcasts this message using User Data Packet(UDP) to the entire network. All subscribing computers with RVDs on the network will receive this message. RVD will filter the messages which non-subscribers will not be notified of the message. Therefore only subscriber programs to the particular topic will get the messages.
So when to use Tibco RV and when to use Tibco EMS (or any other hub-and-spoke model). An article at http://eaiblueprint.com/3.0/?p=17 describes the trade-offs between the two models:
Excerpt:
In my opinion, the multicast-based publish/subscribe messaging is an excellent solution for near-real-time message dissemination when 1 to 'very-many' delivery capabilities matter. RV originated on the trading floors as a vehicle for disseminating financial information such as stock prices.
However, in most EAI cases the opposite requirements are true:
‘Cardinality’ of message delivery is 1-1, 1-2; 1 to-very-many is a rare case. With exception of ‘consolidated application’ integration model (near real time request reply with timeout heuristics), reliability of message delivery takes priority over performance. Effectively, in most EAI implementations of RV, RV ends up simulating a queueing system using its ‘Certified Delivery’ mechanism. While this works, it is a flawed solution (see the discussion of Certified Messaging below).
Reliable delivery is a ‘native’ function of hub-and-spoke solutions. The multicast solution must be augmented with local persistence mechanism and re-try mechanism.
While RV offers reliable delivery (queueing) referred to as Certified Messaging, this solution is flawed in that: Inherently, reliability of CM is not comparable to the hub-and-spoke topologies as the data is stored in local file systems using non-transactional disk operations, as opposed to centralized database in hub-and-spoke topology. Corruption of RV ‘ledger files’ is not a rare case that leads to loss of data. Temporal de-coupling is not the case. While a message can be queue for a later delivery (in case the target system is unavailable), for a message to be actually delivered both system must be up at the same time.
RV / CM lacks a basic facility of any queueing system: a queue browser that is frequently required for production support (for example, in order to remove an offending message). In contrast, MQ Series offers an out-of the box queue browser and a host of third party solutions. Transactional messaging is difficult to implement in multicast environment. TIBCO offers a transactional augmentation of RV (RVTX) that guarantees a 1-and-onlu-once delivery; however, this solution essentially converts RV into a hub-and-spoke system. Consequently, very few RV implementations are transactional.
Having said that, the shortcomings of hub and spoke include:
- Single point of failure, when the hub is down, everything is down. MQ Series addresses this problem by providing high-reliability clustering.
- Non-native publish/subscriber (publish/subscribe is emulated programmatically ) that results in reduced performance, especially in 1-to-very many delivery
- Overhead of hub management (a need for administering hub objects: queues, channels, etc).
- Inferior performance, especially in 1 to-many publish/subscribe and request/reply cases.
These shortcomings — in my opinion — do not outweigh benefits and for that reason MQ Series / hub-and-spoke solutions constitute a better choice for most EAI problem. Multicast-based publish subscribe is better left to its niches (high volume, high performance, accepter unreliability, 1 to very many).
Monday, January 30, 2006
ATMI vs Corba OTS
Recently while working on BEA Tuxedo server, I came across the term 'ATMI' - Application to Transaction Monitor Interface. I beleive Tux was quite a popular product for handling large number of transactions in a distributed environment - right from the early days when most business critical applications were written in Cobol.
ATMI is a procedural, non object oriented API that you use to write stateless services to manage transactions. This API is developed by the OpenGroup and forms the core service API of Tuxedo. The Application-Transaction Monitor Interface (ATMI) provides the interface between the COBOL application and the transaction processing system. This interface is known as ATMI and these pages specify its COBOL language binding. It provides routines to open and close resources, manage transactions, manage record types, and invoke request/response and conversational service calls.
But I believe today's TP monitors are based on Corba OTS (Object Transaction service) semantics. Corba OTS is used by any OO application as the underlying semantics for communications with resouce managers in a distributed transaction. Even JTS is the Java langauge mapping of Corba OTS. A JTS transaction manager implements the Java mappings of the CORBA OTS 1.1 specification, specifically, the Java packages org.omg.CosTransactions and org.omg.CosTSPortability. A JTS transaction manager can propagate transaction contexts to another JTS transaction manager via IIOP.
ATMI is a procedural, non object oriented API that you use to write stateless services to manage transactions. This API is developed by the OpenGroup and forms the core service API of Tuxedo. The Application-Transaction Monitor Interface (ATMI) provides the interface between the COBOL application and the transaction processing system. This interface is known as ATMI and these pages specify its COBOL language binding. It provides routines to open and close resources, manage transactions, manage record types, and invoke request/response and conversational service calls.
But I believe today's TP monitors are based on Corba OTS (Object Transaction service) semantics. Corba OTS is used by any OO application as the underlying semantics for communications with resouce managers in a distributed transaction. Even JTS is the Java langauge mapping of Corba OTS. A JTS transaction manager implements the Java mappings of the CORBA OTS 1.1 specification, specifically, the Java packages org.omg.CosTransactions and org.omg.CosTSPortability. A JTS transaction manager can propagate transaction contexts to another JTS transaction manager via IIOP.
Friday, January 27, 2006
Having both HTTP and HTTPS in a web-application
Web applications often need to have both http and https access; i.e. some URIs in the web application need to have HTTPS access and some can do with HTTP.
Hard-coding the URL address with https whereever required is not an elegant solution as this has to be reflected in all the links in all pages. An alternative soln will be to do a Response.redirect from the page with https in the URL. More detailed info is available at :
http://www.javaworld.com/javaworld/jw-02-2002/jw-0215-ssl.html
Also Struts has a extension through which we can specify which URLs need HTTPS access. For more info check out:
http://struts.apache.org/struts-taglib/ssl.html
http://sslext.sourceforge.net/
Hard-coding the URL address with https whereever required is not an elegant solution as this has to be reflected in all the links in all pages. An alternative soln will be to do a Response.redirect from the page with https in the URL. More detailed info is available at :
http://www.javaworld.com/javaworld/jw-02-2002/jw-0215-ssl.html
Also Struts has a extension through which we can specify which URLs need HTTPS access. For more info check out:
http://struts.apache.org/struts-taglib/ssl.html
http://sslext.sourceforge.net/
Java Service Wrapper
Came across this tool that can be used to run Java apps as a Windows Service or Unix deamon.
Includes fault correction software to automatically restart crashed or frozen JVMs. Critical when app is needed 24x7. Built for flexibility.
The following links provide more info:
http://sourceforge.net/projects/wrapper/ http://wrapper.tanukisoftware.org/doc/english/introduction.html
Includes fault correction software to automatically restart crashed or frozen JVMs. Critical when app is needed 24x7. Built for flexibility.
The following links provide more info:
http://sourceforge.net/projects/wrapper/ http://wrapper.tanukisoftware.org/doc/english/introduction.html
How to gaurantee "Once-and-only-once" delivery in JMS
In one application scenario, it was required to process the message only once. The message contained a donation amount that needed to be put in the database. Using a Queue and AUTO_ACK semantics, we were able to achieve this. But there was a problem - What would happen if the JMS provider fails before the acknowledgement is received from client. It would send the message again when it comes up. How to avoid this ?
The consumer may receive the message again, because when delivery is guaranteed, it's better to risk delivering a message twice than to risk losing it entirely. A redelivered message will have the JMSRedelivered flag set. A client application can check this flag by calling the getJMSRedelivered() method on the Message object. Only the most recent message received is subject to this ambiguity.
The consumer may receive the message again, because when delivery is guaranteed, it's better to risk delivering a message twice than to risk losing it entirely. A redelivered message will have the JMSRedelivered flag set. A client application can check this flag by calling the getJMSRedelivered() method on the Message object. Only the most recent message received is subject to this ambiguity.
What are XA transactions? What is a XA datasource?
Came across this wonderful explanation by Mike regarding XA transactions here
Excerpt:
An XA transaction, in the most general terms, is a "global transaction" that may span multiple resources. A non-XA transaction always involves just one resource. An XA transaction involves a coordinating transaction manager, with one or more databases (or other resources, like JMS) all involved in a single global transaction. Non-XA transactions have no transaction coordinator, and a single resource is doing all its transaction work itself (this is sometimes called local transactions).
XA transactions come from the X/Open group specification on distributed, global transactions. JTA includes the X/Open XA spec, in modified form. Most stuff in the world is non-XA - a Servlet or EJB or plain old JDBC in a Java application talking to a single database. XA gets involved when you want to work with multiple resources - 2 or more databases, a database and a JMS connection, all of those plus maybe a JCA resource - all in a single transaction. In this scenario, you'll have an app server like Websphere or Weblogic or JBoss acting as the Transaction Manager, and your various resources (Oracle, Sybase, IBM MQ JMS, SAP, whatever) acting as transaction resources. Your code can then update/delete/publish/whatever across the many resources. When you say "commit", the results are commited across all of the resources. When you say "rollback", _everything_ is rolled back across all resources.
The Transaction Manager coordinates all of this through a protocol called Two Phase Commit (2PC). This protocol also has to be supported by the individual resources. In terms of datasources, an XA datasource is a data source that can participate in an XA global transaction. A non-XA datasource generally can't participate in a global transaction (sort of - some people implement what's called a "last participant" optimization that can let you do this for exactly one non-XA item).
Excerpt:
An XA transaction, in the most general terms, is a "global transaction" that may span multiple resources. A non-XA transaction always involves just one resource. An XA transaction involves a coordinating transaction manager, with one or more databases (or other resources, like JMS) all involved in a single global transaction. Non-XA transactions have no transaction coordinator, and a single resource is doing all its transaction work itself (this is sometimes called local transactions).
XA transactions come from the X/Open group specification on distributed, global transactions. JTA includes the X/Open XA spec, in modified form. Most stuff in the world is non-XA - a Servlet or EJB or plain old JDBC in a Java application talking to a single database. XA gets involved when you want to work with multiple resources - 2 or more databases, a database and a JMS connection, all of those plus maybe a JCA resource - all in a single transaction. In this scenario, you'll have an app server like Websphere or Weblogic or JBoss acting as the Transaction Manager, and your various resources (Oracle, Sybase, IBM MQ JMS, SAP, whatever) acting as transaction resources. Your code can then update/delete/publish/whatever across the many resources. When you say "commit", the results are commited across all of the resources. When you say "rollback", _everything_ is rolled back across all resources.
The Transaction Manager coordinates all of this through a protocol called Two Phase Commit (2PC). This protocol also has to be supported by the individual resources. In terms of datasources, an XA datasource is a data source that can participate in an XA global transaction. A non-XA datasource generally can't participate in a global transaction (sort of - some people implement what's called a "last participant" optimization that can let you do this for exactly one non-XA item).
Wednesday, January 25, 2006
Message Driven Beans Vs Stand-alone JMS clients
In many design scenarios, asynchronous messaging is required- for integration purposes, for handling large volume of requests etc.
In the J2EE scenario, we often have to decide whether to write a simple JMS client or go for a MDB in a EJB container. Though, a simple JMS client is neat and easy to write, it has some disadvantages:
JMS has no built-in mechanism to handle more than one incoming request at a time. To support concurrent requests, you will need to extend the JMS client to spawn multiple threads, or launch multiple JVM instances, each running the application.On the downside, we have issues of security, transaction handling, and scalability.
The main advantage that MDBs have over simple JMS message consumers is that the EJB container can instantiate multiple MDB instances to handle multiple messages simultaneously.
A message-driven bean (MDB) acts as a JMS message listener. MDBs are different from session beans and entity beans because they have no remote, remote home, local, or local home interfaces. They are similar to other bean types in that they have a bean implementation, they are defined in the ejb-jar.xml file, and they can take advantage of EJB features such as transactions, security, and lifecycle management.
As a full-fledged JMS client, MDBs can both send and receive messages asynchronously via a MOM server. As an enterprise bean, MDBs are managed by the container and declaratively configured by an EJB deployment descriptor.
For instance, a JMS client could send a message to an MDB (which is constantly online awaiting incoming messages), which in turn could access a session bean or a handful of entity beans. In this way, MDBs can be used as a sort of an asynchronous wrapper, providing access to business processes that could previously be accessed only via a synchronous RMI/IIOP call.
Because they are specifically designed as message consumers and yet are still managed by the EJB container, MDBs offer a tremendous advantage in terms of scalability. Because message beans are stateless and managed by the container, they can both send and receive messages concurrently (the container simply grabs another bean out of the pool). This, combined with the inherent scalability of EJB application servers, produces a very robust and scalable enterprise messaging solution.
They cannot be invoked in any manner other than via a JMS message. This means that they are ideally suited as message consumers, but not necessarily as message producers. Message-driven beans can certainly send messages, but only after first being invoked by an incoming request. Also, MDBs are currently designed to map to only a single JMS destination. They listen for messages on that destination only.
When a message-driven bean's transaction attribute is set to Required, then the message delivery from the JMS destination to the message-driven bean is part of the subsequent transactional work undertaken by the bean. By having the message-driven bean be part of a transaction, you ensure that message delivery takes place. If the subsequent transactional work that the message-driven bean starts does not go to completion, then, when the container rolls back that transactional work it also puts the message back in its destination so that it can be picked up later by another message-driven bean instance.
One limitation of message-driven beans compared to standard JMS listeners is that you can associate a given message-driven bean deployment with only one Queue or Topic
If your application requires a single JMS consumer to service messages from multiple Queues or Topics, you must use a standard JMS consumer, or deploy multiple message-driven bean classes.
In the J2EE scenario, we often have to decide whether to write a simple JMS client or go for a MDB in a EJB container. Though, a simple JMS client is neat and easy to write, it has some disadvantages:
JMS has no built-in mechanism to handle more than one incoming request at a time. To support concurrent requests, you will need to extend the JMS client to spawn multiple threads, or launch multiple JVM instances, each running the application.On the downside, we have issues of security, transaction handling, and scalability.
The main advantage that MDBs have over simple JMS message consumers is that the EJB container can instantiate multiple MDB instances to handle multiple messages simultaneously.
A message-driven bean (MDB) acts as a JMS message listener. MDBs are different from session beans and entity beans because they have no remote, remote home, local, or local home interfaces. They are similar to other bean types in that they have a bean implementation, they are defined in the ejb-jar.xml file, and they can take advantage of EJB features such as transactions, security, and lifecycle management.
As a full-fledged JMS client, MDBs can both send and receive messages asynchronously via a MOM server. As an enterprise bean, MDBs are managed by the container and declaratively configured by an EJB deployment descriptor.
For instance, a JMS client could send a message to an MDB (which is constantly online awaiting incoming messages), which in turn could access a session bean or a handful of entity beans. In this way, MDBs can be used as a sort of an asynchronous wrapper, providing access to business processes that could previously be accessed only via a synchronous RMI/IIOP call.
Because they are specifically designed as message consumers and yet are still managed by the EJB container, MDBs offer a tremendous advantage in terms of scalability. Because message beans are stateless and managed by the container, they can both send and receive messages concurrently (the container simply grabs another bean out of the pool). This, combined with the inherent scalability of EJB application servers, produces a very robust and scalable enterprise messaging solution.
They cannot be invoked in any manner other than via a JMS message. This means that they are ideally suited as message consumers, but not necessarily as message producers. Message-driven beans can certainly send messages, but only after first being invoked by an incoming request. Also, MDBs are currently designed to map to only a single JMS destination. They listen for messages on that destination only.
When a message-driven bean's transaction attribute is set to Required, then the message delivery from the JMS destination to the message-driven bean is part of the subsequent transactional work undertaken by the bean. By having the message-driven bean be part of a transaction, you ensure that message delivery takes place. If the subsequent transactional work that the message-driven bean starts does not go to completion, then, when the container rolls back that transactional work it also puts the message back in its destination so that it can be picked up later by another message-driven bean instance.
One limitation of message-driven beans compared to standard JMS listeners is that you can associate a given message-driven bean deployment with only one Queue or Topic
If your application requires a single JMS consumer to service messages from multiple Queues or Topics, you must use a standard JMS consumer, or deploy multiple message-driven bean classes.
Tuesday, January 17, 2006
On Screen Scraping
Recently I came across the term "Screen Scraping" when interfacing with a legacy application. I was not really sure what it mean in the context of EAI.. A google search came up with a good explanation at http://en.wikipedia.org/wiki/Screen_scraping
As a concrete example of a classic screen scraper, consider a hypothetical legacy system dating from the 1960s -- the dawn of computerized data processing. Computer to user interfaces from that era were often simply text-based dumb terminals which were not much more than virtual teleprinters. (Such systems are still in use today, for various reasons.) The desire to interface such a system to more modern systems is common. An elegant solution will often require things no longer available, such as source code, system documentation, APIs, and/or programmers with experience in a 45 year old computer system. In such cases, the only feasible solution may be to write a screen scraper which "pretends" to be a user at a terminal. The screen scraper might connect to the legacy system via Telnet, emulator the keystrokes needed to navigate the old user interface, process the resulting display output, extract the desired data, and pass it on to the modern system.
As a concrete example of a classic screen scraper, consider a hypothetical legacy system dating from the 1960s -- the dawn of computerized data processing. Computer to user interfaces from that era were often simply text-based dumb terminals which were not much more than virtual teleprinters. (Such systems are still in use today, for various reasons.) The desire to interface such a system to more modern systems is common. An elegant solution will often require things no longer available, such as source code, system documentation, APIs, and/or programmers with experience in a 45 year old computer system. In such cases, the only feasible solution may be to write a screen scraper which "pretends" to be a user at a terminal. The screen scraper might connect to the legacy system via Telnet, emulator the keystrokes needed to navigate the old user interface, process the resulting display output, extract the desired data, and pass it on to the modern system.
Subscribe to:
Posts (Atom)