Recently I had to move my MySQL server from a WinXP machine to a Win2000 server machine. I thought that the data migration of the MySQl database would be a pain.
To my suprise, it just took me 5 mins flat to do it. Here are the steps:
1)First export the database into a flat file. This exports not just the schema but also the "insert" statements for all the data in the tables
mysqldump -u DBUSER -p DBNAME > DBNAME.sql
substituting DBUSER with your MySQL username and DBNAME with your database name.
2) Create a new empty schema/database on your new machine. The name of the database will probably be same as the name in the old server.
3) Import the dump file into the new database server.
mysql -u DBUSER -p -h MACHINE-NAME DBNAME< DBName.sql
substituting DBUSER with your MySQL username and DBNAME with your database name, and MACHINE-NAME with the name of the SQLServer instance - quite often the name of the machine itself.
That's it...migration of database done.
Tuesday, February 28, 2006
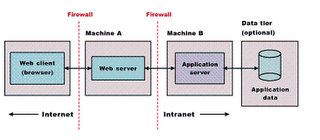
Why put a webserver in front of an application server?
A lot of my developer friends pop up the question of why to use a webserver when today's application servers such as Weblogic, Websphere, Tomcat, JBoss etc. also have a HTTP listener. But in almost every architecture, we will see Apache in front of Tomcat, or IBM Http Server in front of WAS. The question is why?...and the answers are as follows:
- Webservers serve static content faster than application servers. Hence for performace reasons, it makes sense to shift all the static contect to the webserver. (J2EE developers hate this, as they now have to split the *.war files)
- The webserver can be put in a DMZ to enable enhanced security.
- The webserver can be used as a load balancer over multiple application server instances.
- The webserver can have agents/plug-in's to security servers such as Netegrity. Hence security is taken care by the webserver, putting less load on the application server.
What is a DMZ?
DMZ stands for demilitarized zone. DMZ is also known as perimeter network and is used for security purposes. A DMZ is that part of the network/subnet that sits between the organisations LAN and the Internet. The concept behind creating a DMZ is that m/c's from the Internet and the org's LAN can connect to DMZ, but the DMZ can only connect to the external network - i.e. the Internet.
This allows m/c's hosted in the DMZ to interact with the external network for services such as Email, Web and DNS. So even if a host in the DMZ is compromised, the internal network is still safe. Connections from the external network to the DMZ are usually controlled using port address translation (PAT).
A DMZ can be created by connecting each network to different ports of a single firewall (3-legged-firewall) or by having 2 firewalls and the area btw them as a DMZ.
In case of Enterprise Applications (3-layered), the webserver is placed in the DMZ. This protects the applications business logic and database from intruder attacks.
This allows m/c's hosted in the DMZ to interact with the external network for services such as Email, Web and DNS. So even if a host in the DMZ is compromised, the internal network is still safe. Connections from the external network to the DMZ are usually controlled using port address translation (PAT).
A DMZ can be created by connecting each network to different ports of a single firewall (3-legged-firewall) or by having 2 firewalls and the area btw them as a DMZ.
In case of Enterprise Applications (3-layered), the webserver is placed in the DMZ. This protects the applications business logic and database from intruder attacks.

Friday, February 24, 2006
Citrix Server and Terminal Services
I was quite familiar with Terminal Services in Windows and also the Remote Desktop Protocol used in it. But recently I came across a technology called 'Citrix' that was similar in nature, so I decided to dig into the root of it. This is the info I found on the net:
Citrix Presentation ServerSoftware from Citrix that provides a timeshared, multiuser environment for Unix and Windows servers. Formerly MetaFrame, Citrix Presentation Server uses the ICA protocol to turn the client machine into a terminal and governs the input/output between the client and server. Applications can also be run from a Web browser
Citrix Presentation Server (formerly Citrix MetaFrame) is a remote access/application publishing product built on the Independent Computing Architecture (ICA), Citrix Systems' thin client protocol. The Microsoft Remote Desktop Protocol, part of Microsoft's Terminal Services, is based on Citrix technology and was licensed from Citrix in 1997. Unlike traditional framebuffered protocols like VNC, ICA transmits high-level window display information, much like the X11 protocol, as opposed to purely graphical information.
Independent Computing Architecture (ICA) is a proprietary protocol for an application server system, designed by Citrix Systems. The protocol lays down a specification for passing data between server and clients, but is not bound to any one platform.
Practical products conforming to ICA are Citrix's WinFrame and MetaFrame products. These permit ordinary Windows applications to be run on a suitable Windows server, and for any supported client to gain access to those applications. The client platforms need not run Windows, there are clients for Mac and Unix for example.
Citrix Presentation ServerSoftware from Citrix that provides a timeshared, multiuser environment for Unix and Windows servers. Formerly MetaFrame, Citrix Presentation Server uses the ICA protocol to turn the client machine into a terminal and governs the input/output between the client and server. Applications can also be run from a Web browser
Citrix Presentation Server (formerly Citrix MetaFrame) is a remote access/application publishing product built on the Independent Computing Architecture (ICA), Citrix Systems' thin client protocol. The Microsoft Remote Desktop Protocol, part of Microsoft's Terminal Services, is based on Citrix technology and was licensed from Citrix in 1997. Unlike traditional framebuffered protocols like VNC, ICA transmits high-level window display information, much like the X11 protocol, as opposed to purely graphical information.
Independent Computing Architecture (ICA) is a proprietary protocol for an application server system, designed by Citrix Systems. The protocol lays down a specification for passing data between server and clients, but is not bound to any one platform.
Practical products conforming to ICA are Citrix's WinFrame and MetaFrame products. These permit ordinary Windows applications to be run on a suitable Windows server, and for any supported client to gain access to those applications. The client platforms need not run Windows, there are clients for Mac and Unix for example.
Tuesday, January 31, 2006
Tibco RV vs Tibco EMS
A lot of people are familiar with the Tibco RV (Rendezvous) product. This product is around 20 years old and powers many mission critical systems across different domains. Tibco has another product called Tibco EMS (Enterprise messaging Server) which is based on the JMS hub-and-spoke model and is quite popular in EAI. So what's the difference btw the two products? - When to use what ?
First we need to understand the differences in the architecture between the two products. Tibco RV is based on the multicast publish/subscribe model, where as Tibco EMS is based on the hub-and-spoke model.
Multicast is the delivery of information to a group of destinations simultaneously using the most efficient strategy to deliver the messages over each link of the network only once and only create copies when the links to the destinations split. By comparison with multicast, conventional point-to-single-point delivery is called unicast. When unicast is used to deliver to several recipients, a copy of the data is sent from the sender to each recipient, resulting in inefficient and badly scalable duplication at the sending side.
Googled out a white paper that contained some good architecture details about Tibco RV. The link is here.
Excerpt from the article:
TIB/RV is based on a distributed architecture . An installation of TIB/RV resides on each host on the network.Hence it eliminates the bottlenecks and single points offailures could be handled. It allows programs to sendmessages in a reliable, certified and transactional manner,depending on the requirements. Messaging can be delivered in point-to-point or publish/subscribe, synchronously orasynchronously, locally delivered or sent via WAN or theInternet. Rendezvous messages are self-describing and platform independent.
RVD (Rendezvous Daemon) is a background process that sits in between the RVprogram and the network. It is responsible for the deliveryand the acquisition of messages, either in point-to-point or publish/subscribe message domain. It is the most important component of the whole TIB/RV.Theoretically, there is an installation of RVD on every host on the network. However, it is possible to connect to a remote daemon, which sacrifices performance and transparencies. The RV Sender program passes the message and destination topic to RVD. RVD then broadcasts this message using User Data Packet(UDP) to the entire network. All subscribing computers with RVDs on the network will receive this message. RVD will filter the messages which non-subscribers will not be notified of the message. Therefore only subscriber programs to the particular topic will get the messages.
So when to use Tibco RV and when to use Tibco EMS (or any other hub-and-spoke model). An article at http://eaiblueprint.com/3.0/?p=17 describes the trade-offs between the two models:
Excerpt:
In my opinion, the multicast-based publish/subscribe messaging is an excellent solution for near-real-time message dissemination when 1 to 'very-many' delivery capabilities matter. RV originated on the trading floors as a vehicle for disseminating financial information such as stock prices.
However, in most EAI cases the opposite requirements are true:
‘Cardinality’ of message delivery is 1-1, 1-2; 1 to-very-many is a rare case. With exception of ‘consolidated application’ integration model (near real time request reply with timeout heuristics), reliability of message delivery takes priority over performance. Effectively, in most EAI implementations of RV, RV ends up simulating a queueing system using its ‘Certified Delivery’ mechanism. While this works, it is a flawed solution (see the discussion of Certified Messaging below).
Reliable delivery is a ‘native’ function of hub-and-spoke solutions. The multicast solution must be augmented with local persistence mechanism and re-try mechanism.
While RV offers reliable delivery (queueing) referred to as Certified Messaging, this solution is flawed in that: Inherently, reliability of CM is not comparable to the hub-and-spoke topologies as the data is stored in local file systems using non-transactional disk operations, as opposed to centralized database in hub-and-spoke topology. Corruption of RV ‘ledger files’ is not a rare case that leads to loss of data. Temporal de-coupling is not the case. While a message can be queue for a later delivery (in case the target system is unavailable), for a message to be actually delivered both system must be up at the same time.
RV / CM lacks a basic facility of any queueing system: a queue browser that is frequently required for production support (for example, in order to remove an offending message). In contrast, MQ Series offers an out-of the box queue browser and a host of third party solutions. Transactional messaging is difficult to implement in multicast environment. TIBCO offers a transactional augmentation of RV (RVTX) that guarantees a 1-and-onlu-once delivery; however, this solution essentially converts RV into a hub-and-spoke system. Consequently, very few RV implementations are transactional.
Having said that, the shortcomings of hub and spoke include:
First we need to understand the differences in the architecture between the two products. Tibco RV is based on the multicast publish/subscribe model, where as Tibco EMS is based on the hub-and-spoke model.
Multicast is the delivery of information to a group of destinations simultaneously using the most efficient strategy to deliver the messages over each link of the network only once and only create copies when the links to the destinations split. By comparison with multicast, conventional point-to-single-point delivery is called unicast. When unicast is used to deliver to several recipients, a copy of the data is sent from the sender to each recipient, resulting in inefficient and badly scalable duplication at the sending side.
Googled out a white paper that contained some good architecture details about Tibco RV. The link is here.
Excerpt from the article:
TIB/RV is based on a distributed architecture . An installation of TIB/RV resides on each host on the network.Hence it eliminates the bottlenecks and single points offailures could be handled. It allows programs to sendmessages in a reliable, certified and transactional manner,depending on the requirements. Messaging can be delivered in point-to-point or publish/subscribe, synchronously orasynchronously, locally delivered or sent via WAN or theInternet. Rendezvous messages are self-describing and platform independent.
RVD (Rendezvous Daemon) is a background process that sits in between the RVprogram and the network. It is responsible for the deliveryand the acquisition of messages, either in point-to-point or publish/subscribe message domain. It is the most important component of the whole TIB/RV.Theoretically, there is an installation of RVD on every host on the network. However, it is possible to connect to a remote daemon, which sacrifices performance and transparencies. The RV Sender program passes the message and destination topic to RVD. RVD then broadcasts this message using User Data Packet(UDP) to the entire network. All subscribing computers with RVDs on the network will receive this message. RVD will filter the messages which non-subscribers will not be notified of the message. Therefore only subscriber programs to the particular topic will get the messages.
So when to use Tibco RV and when to use Tibco EMS (or any other hub-and-spoke model). An article at http://eaiblueprint.com/3.0/?p=17 describes the trade-offs between the two models:
Excerpt:
In my opinion, the multicast-based publish/subscribe messaging is an excellent solution for near-real-time message dissemination when 1 to 'very-many' delivery capabilities matter. RV originated on the trading floors as a vehicle for disseminating financial information such as stock prices.
However, in most EAI cases the opposite requirements are true:
‘Cardinality’ of message delivery is 1-1, 1-2; 1 to-very-many is a rare case. With exception of ‘consolidated application’ integration model (near real time request reply with timeout heuristics), reliability of message delivery takes priority over performance. Effectively, in most EAI implementations of RV, RV ends up simulating a queueing system using its ‘Certified Delivery’ mechanism. While this works, it is a flawed solution (see the discussion of Certified Messaging below).
Reliable delivery is a ‘native’ function of hub-and-spoke solutions. The multicast solution must be augmented with local persistence mechanism and re-try mechanism.
While RV offers reliable delivery (queueing) referred to as Certified Messaging, this solution is flawed in that: Inherently, reliability of CM is not comparable to the hub-and-spoke topologies as the data is stored in local file systems using non-transactional disk operations, as opposed to centralized database in hub-and-spoke topology. Corruption of RV ‘ledger files’ is not a rare case that leads to loss of data. Temporal de-coupling is not the case. While a message can be queue for a later delivery (in case the target system is unavailable), for a message to be actually delivered both system must be up at the same time.
RV / CM lacks a basic facility of any queueing system: a queue browser that is frequently required for production support (for example, in order to remove an offending message). In contrast, MQ Series offers an out-of the box queue browser and a host of third party solutions. Transactional messaging is difficult to implement in multicast environment. TIBCO offers a transactional augmentation of RV (RVTX) that guarantees a 1-and-onlu-once delivery; however, this solution essentially converts RV into a hub-and-spoke system. Consequently, very few RV implementations are transactional.
Having said that, the shortcomings of hub and spoke include:
- Single point of failure, when the hub is down, everything is down. MQ Series addresses this problem by providing high-reliability clustering.
- Non-native publish/subscriber (publish/subscribe is emulated programmatically ) that results in reduced performance, especially in 1-to-very many delivery
- Overhead of hub management (a need for administering hub objects: queues, channels, etc).
- Inferior performance, especially in 1 to-many publish/subscribe and request/reply cases.
These shortcomings — in my opinion — do not outweigh benefits and for that reason MQ Series / hub-and-spoke solutions constitute a better choice for most EAI problem. Multicast-based publish subscribe is better left to its niches (high volume, high performance, accepter unreliability, 1 to very many).
Monday, January 30, 2006
ATMI vs Corba OTS
Recently while working on BEA Tuxedo server, I came across the term 'ATMI' - Application to Transaction Monitor Interface. I beleive Tux was quite a popular product for handling large number of transactions in a distributed environment - right from the early days when most business critical applications were written in Cobol.
ATMI is a procedural, non object oriented API that you use to write stateless services to manage transactions. This API is developed by the OpenGroup and forms the core service API of Tuxedo. The Application-Transaction Monitor Interface (ATMI) provides the interface between the COBOL application and the transaction processing system. This interface is known as ATMI and these pages specify its COBOL language binding. It provides routines to open and close resources, manage transactions, manage record types, and invoke request/response and conversational service calls.
But I believe today's TP monitors are based on Corba OTS (Object Transaction service) semantics. Corba OTS is used by any OO application as the underlying semantics for communications with resouce managers in a distributed transaction. Even JTS is the Java langauge mapping of Corba OTS. A JTS transaction manager implements the Java mappings of the CORBA OTS 1.1 specification, specifically, the Java packages org.omg.CosTransactions and org.omg.CosTSPortability. A JTS transaction manager can propagate transaction contexts to another JTS transaction manager via IIOP.
ATMI is a procedural, non object oriented API that you use to write stateless services to manage transactions. This API is developed by the OpenGroup and forms the core service API of Tuxedo. The Application-Transaction Monitor Interface (ATMI) provides the interface between the COBOL application and the transaction processing system. This interface is known as ATMI and these pages specify its COBOL language binding. It provides routines to open and close resources, manage transactions, manage record types, and invoke request/response and conversational service calls.
But I believe today's TP monitors are based on Corba OTS (Object Transaction service) semantics. Corba OTS is used by any OO application as the underlying semantics for communications with resouce managers in a distributed transaction. Even JTS is the Java langauge mapping of Corba OTS. A JTS transaction manager implements the Java mappings of the CORBA OTS 1.1 specification, specifically, the Java packages org.omg.CosTransactions and org.omg.CosTSPortability. A JTS transaction manager can propagate transaction contexts to another JTS transaction manager via IIOP.
Friday, January 27, 2006
Having both HTTP and HTTPS in a web-application
Web applications often need to have both http and https access; i.e. some URIs in the web application need to have HTTPS access and some can do with HTTP.
Hard-coding the URL address with https whereever required is not an elegant solution as this has to be reflected in all the links in all pages. An alternative soln will be to do a Response.redirect from the page with https in the URL. More detailed info is available at :
http://www.javaworld.com/javaworld/jw-02-2002/jw-0215-ssl.html
Also Struts has a extension through which we can specify which URLs need HTTPS access. For more info check out:
http://struts.apache.org/struts-taglib/ssl.html
http://sslext.sourceforge.net/
Hard-coding the URL address with https whereever required is not an elegant solution as this has to be reflected in all the links in all pages. An alternative soln will be to do a Response.redirect from the page with https in the URL. More detailed info is available at :
http://www.javaworld.com/javaworld/jw-02-2002/jw-0215-ssl.html
Also Struts has a extension through which we can specify which URLs need HTTPS access. For more info check out:
http://struts.apache.org/struts-taglib/ssl.html
http://sslext.sourceforge.net/
Java Service Wrapper
Came across this tool that can be used to run Java apps as a Windows Service or Unix deamon.
Includes fault correction software to automatically restart crashed or frozen JVMs. Critical when app is needed 24x7. Built for flexibility.
The following links provide more info:
http://sourceforge.net/projects/wrapper/ http://wrapper.tanukisoftware.org/doc/english/introduction.html
Includes fault correction software to automatically restart crashed or frozen JVMs. Critical when app is needed 24x7. Built for flexibility.
The following links provide more info:
http://sourceforge.net/projects/wrapper/ http://wrapper.tanukisoftware.org/doc/english/introduction.html
How to gaurantee "Once-and-only-once" delivery in JMS
In one application scenario, it was required to process the message only once. The message contained a donation amount that needed to be put in the database. Using a Queue and AUTO_ACK semantics, we were able to achieve this. But there was a problem - What would happen if the JMS provider fails before the acknowledgement is received from client. It would send the message again when it comes up. How to avoid this ?
The consumer may receive the message again, because when delivery is guaranteed, it's better to risk delivering a message twice than to risk losing it entirely. A redelivered message will have the JMSRedelivered flag set. A client application can check this flag by calling the getJMSRedelivered() method on the Message object. Only the most recent message received is subject to this ambiguity.
The consumer may receive the message again, because when delivery is guaranteed, it's better to risk delivering a message twice than to risk losing it entirely. A redelivered message will have the JMSRedelivered flag set. A client application can check this flag by calling the getJMSRedelivered() method on the Message object. Only the most recent message received is subject to this ambiguity.
What are XA transactions? What is a XA datasource?
Came across this wonderful explanation by Mike regarding XA transactions here
Excerpt:
An XA transaction, in the most general terms, is a "global transaction" that may span multiple resources. A non-XA transaction always involves just one resource. An XA transaction involves a coordinating transaction manager, with one or more databases (or other resources, like JMS) all involved in a single global transaction. Non-XA transactions have no transaction coordinator, and a single resource is doing all its transaction work itself (this is sometimes called local transactions).
XA transactions come from the X/Open group specification on distributed, global transactions. JTA includes the X/Open XA spec, in modified form. Most stuff in the world is non-XA - a Servlet or EJB or plain old JDBC in a Java application talking to a single database. XA gets involved when you want to work with multiple resources - 2 or more databases, a database and a JMS connection, all of those plus maybe a JCA resource - all in a single transaction. In this scenario, you'll have an app server like Websphere or Weblogic or JBoss acting as the Transaction Manager, and your various resources (Oracle, Sybase, IBM MQ JMS, SAP, whatever) acting as transaction resources. Your code can then update/delete/publish/whatever across the many resources. When you say "commit", the results are commited across all of the resources. When you say "rollback", _everything_ is rolled back across all resources.
The Transaction Manager coordinates all of this through a protocol called Two Phase Commit (2PC). This protocol also has to be supported by the individual resources. In terms of datasources, an XA datasource is a data source that can participate in an XA global transaction. A non-XA datasource generally can't participate in a global transaction (sort of - some people implement what's called a "last participant" optimization that can let you do this for exactly one non-XA item).
Excerpt:
An XA transaction, in the most general terms, is a "global transaction" that may span multiple resources. A non-XA transaction always involves just one resource. An XA transaction involves a coordinating transaction manager, with one or more databases (or other resources, like JMS) all involved in a single global transaction. Non-XA transactions have no transaction coordinator, and a single resource is doing all its transaction work itself (this is sometimes called local transactions).
XA transactions come from the X/Open group specification on distributed, global transactions. JTA includes the X/Open XA spec, in modified form. Most stuff in the world is non-XA - a Servlet or EJB or plain old JDBC in a Java application talking to a single database. XA gets involved when you want to work with multiple resources - 2 or more databases, a database and a JMS connection, all of those plus maybe a JCA resource - all in a single transaction. In this scenario, you'll have an app server like Websphere or Weblogic or JBoss acting as the Transaction Manager, and your various resources (Oracle, Sybase, IBM MQ JMS, SAP, whatever) acting as transaction resources. Your code can then update/delete/publish/whatever across the many resources. When you say "commit", the results are commited across all of the resources. When you say "rollback", _everything_ is rolled back across all resources.
The Transaction Manager coordinates all of this through a protocol called Two Phase Commit (2PC). This protocol also has to be supported by the individual resources. In terms of datasources, an XA datasource is a data source that can participate in an XA global transaction. A non-XA datasource generally can't participate in a global transaction (sort of - some people implement what's called a "last participant" optimization that can let you do this for exactly one non-XA item).
Wednesday, January 25, 2006
Message Driven Beans Vs Stand-alone JMS clients
In many design scenarios, asynchronous messaging is required- for integration purposes, for handling large volume of requests etc.
In the J2EE scenario, we often have to decide whether to write a simple JMS client or go for a MDB in a EJB container. Though, a simple JMS client is neat and easy to write, it has some disadvantages:
JMS has no built-in mechanism to handle more than one incoming request at a time. To support concurrent requests, you will need to extend the JMS client to spawn multiple threads, or launch multiple JVM instances, each running the application.On the downside, we have issues of security, transaction handling, and scalability.
The main advantage that MDBs have over simple JMS message consumers is that the EJB container can instantiate multiple MDB instances to handle multiple messages simultaneously.
A message-driven bean (MDB) acts as a JMS message listener. MDBs are different from session beans and entity beans because they have no remote, remote home, local, or local home interfaces. They are similar to other bean types in that they have a bean implementation, they are defined in the ejb-jar.xml file, and they can take advantage of EJB features such as transactions, security, and lifecycle management.
As a full-fledged JMS client, MDBs can both send and receive messages asynchronously via a MOM server. As an enterprise bean, MDBs are managed by the container and declaratively configured by an EJB deployment descriptor.
For instance, a JMS client could send a message to an MDB (which is constantly online awaiting incoming messages), which in turn could access a session bean or a handful of entity beans. In this way, MDBs can be used as a sort of an asynchronous wrapper, providing access to business processes that could previously be accessed only via a synchronous RMI/IIOP call.
Because they are specifically designed as message consumers and yet are still managed by the EJB container, MDBs offer a tremendous advantage in terms of scalability. Because message beans are stateless and managed by the container, they can both send and receive messages concurrently (the container simply grabs another bean out of the pool). This, combined with the inherent scalability of EJB application servers, produces a very robust and scalable enterprise messaging solution.
They cannot be invoked in any manner other than via a JMS message. This means that they are ideally suited as message consumers, but not necessarily as message producers. Message-driven beans can certainly send messages, but only after first being invoked by an incoming request. Also, MDBs are currently designed to map to only a single JMS destination. They listen for messages on that destination only.
When a message-driven bean's transaction attribute is set to Required, then the message delivery from the JMS destination to the message-driven bean is part of the subsequent transactional work undertaken by the bean. By having the message-driven bean be part of a transaction, you ensure that message delivery takes place. If the subsequent transactional work that the message-driven bean starts does not go to completion, then, when the container rolls back that transactional work it also puts the message back in its destination so that it can be picked up later by another message-driven bean instance.
One limitation of message-driven beans compared to standard JMS listeners is that you can associate a given message-driven bean deployment with only one Queue or Topic
If your application requires a single JMS consumer to service messages from multiple Queues or Topics, you must use a standard JMS consumer, or deploy multiple message-driven bean classes.
In the J2EE scenario, we often have to decide whether to write a simple JMS client or go for a MDB in a EJB container. Though, a simple JMS client is neat and easy to write, it has some disadvantages:
JMS has no built-in mechanism to handle more than one incoming request at a time. To support concurrent requests, you will need to extend the JMS client to spawn multiple threads, or launch multiple JVM instances, each running the application.On the downside, we have issues of security, transaction handling, and scalability.
The main advantage that MDBs have over simple JMS message consumers is that the EJB container can instantiate multiple MDB instances to handle multiple messages simultaneously.
A message-driven bean (MDB) acts as a JMS message listener. MDBs are different from session beans and entity beans because they have no remote, remote home, local, or local home interfaces. They are similar to other bean types in that they have a bean implementation, they are defined in the ejb-jar.xml file, and they can take advantage of EJB features such as transactions, security, and lifecycle management.
As a full-fledged JMS client, MDBs can both send and receive messages asynchronously via a MOM server. As an enterprise bean, MDBs are managed by the container and declaratively configured by an EJB deployment descriptor.
For instance, a JMS client could send a message to an MDB (which is constantly online awaiting incoming messages), which in turn could access a session bean or a handful of entity beans. In this way, MDBs can be used as a sort of an asynchronous wrapper, providing access to business processes that could previously be accessed only via a synchronous RMI/IIOP call.
Because they are specifically designed as message consumers and yet are still managed by the EJB container, MDBs offer a tremendous advantage in terms of scalability. Because message beans are stateless and managed by the container, they can both send and receive messages concurrently (the container simply grabs another bean out of the pool). This, combined with the inherent scalability of EJB application servers, produces a very robust and scalable enterprise messaging solution.
They cannot be invoked in any manner other than via a JMS message. This means that they are ideally suited as message consumers, but not necessarily as message producers. Message-driven beans can certainly send messages, but only after first being invoked by an incoming request. Also, MDBs are currently designed to map to only a single JMS destination. They listen for messages on that destination only.
When a message-driven bean's transaction attribute is set to Required, then the message delivery from the JMS destination to the message-driven bean is part of the subsequent transactional work undertaken by the bean. By having the message-driven bean be part of a transaction, you ensure that message delivery takes place. If the subsequent transactional work that the message-driven bean starts does not go to completion, then, when the container rolls back that transactional work it also puts the message back in its destination so that it can be picked up later by another message-driven bean instance.
One limitation of message-driven beans compared to standard JMS listeners is that you can associate a given message-driven bean deployment with only one Queue or Topic
If your application requires a single JMS consumer to service messages from multiple Queues or Topics, you must use a standard JMS consumer, or deploy multiple message-driven bean classes.
Tuesday, January 17, 2006
On Screen Scraping
Recently I came across the term "Screen Scraping" when interfacing with a legacy application. I was not really sure what it mean in the context of EAI.. A google search came up with a good explanation at http://en.wikipedia.org/wiki/Screen_scraping
As a concrete example of a classic screen scraper, consider a hypothetical legacy system dating from the 1960s -- the dawn of computerized data processing. Computer to user interfaces from that era were often simply text-based dumb terminals which were not much more than virtual teleprinters. (Such systems are still in use today, for various reasons.) The desire to interface such a system to more modern systems is common. An elegant solution will often require things no longer available, such as source code, system documentation, APIs, and/or programmers with experience in a 45 year old computer system. In such cases, the only feasible solution may be to write a screen scraper which "pretends" to be a user at a terminal. The screen scraper might connect to the legacy system via Telnet, emulator the keystrokes needed to navigate the old user interface, process the resulting display output, extract the desired data, and pass it on to the modern system.
As a concrete example of a classic screen scraper, consider a hypothetical legacy system dating from the 1960s -- the dawn of computerized data processing. Computer to user interfaces from that era were often simply text-based dumb terminals which were not much more than virtual teleprinters. (Such systems are still in use today, for various reasons.) The desire to interface such a system to more modern systems is common. An elegant solution will often require things no longer available, such as source code, system documentation, APIs, and/or programmers with experience in a 45 year old computer system. In such cases, the only feasible solution may be to write a screen scraper which "pretends" to be a user at a terminal. The screen scraper might connect to the legacy system via Telnet, emulator the keystrokes needed to navigate the old user interface, process the resulting display output, extract the desired data, and pass it on to the modern system.
Thursday, December 29, 2005
About Daemon Threads in Java
Came across this cool article about Daemon Threads at http://www.absolutejava.com/main-articles/beware-the-daemons/
I knew that the VM does not exit as long as there is one non-daemon thread running. But there were a couple of new things I learned. Some snippets from the above article:
There are two ways a thread can become a daemon thread (or a user thread, for that matter) without putting your soul at risk. First, you can explicitly specify a thread to be a daemon thread by calling setDaemon(true) on a Thread object. Note that the setDaemon() method must be called before the thread's start() method is invoked.Once a thread has started executing (i.e., its start() method has been called) its daemon status cannot be changed.
The second technique for creating a daemon thread is based on an often overlooked feature of Java's threading behavior: If a thread creates a new thread and does not call setDaemon() to explicitlly set the new thread's "daemon status", the new thread inherits the "daemon-status" of the thread that created it. In other words, unless setDaemon(false) is called, all threads created by daemon threads will be daemon threads; similarly, unless setDaemon(true) is called, all threads created by user threads will be user threads.
I knew that the VM does not exit as long as there is one non-daemon thread running. But there were a couple of new things I learned. Some snippets from the above article:
There are two ways a thread can become a daemon thread (or a user thread, for that matter) without putting your soul at risk. First, you can explicitly specify a thread to be a daemon thread by calling setDaemon(true) on a Thread object. Note that the setDaemon() method must be called before the thread's start() method is invoked.Once a thread has started executing (i.e., its start() method has been called) its daemon status cannot be changed.
The second technique for creating a daemon thread is based on an often overlooked feature of Java's threading behavior: If a thread creates a new thread and does not call setDaemon() to explicitlly set the new thread's "daemon status", the new thread inherits the "daemon-status" of the thread that created it. In other words, unless setDaemon(false) is called, all threads created by daemon threads will be daemon threads; similarly, unless setDaemon(true) is called, all threads created by user threads will be user threads.
Monday, December 26, 2005
Debug information in Java .class files
I have often wanted to learn more about the class file format of Java class files. This study let me to interesting discoveries - regarding what debug information is stored in class files and how it is stored.
When we compile a Java source using the 'javac' exe, the generated class file by default contains some debug info - By default, only the line number and source file information is generated.
Hence when a stack trace is printed on the screen, we can see the source file name and the line number also printed on the screen. Also, when using log4J, I remember using a layout which can print the line number of each log statement - I bet log4J uses the debug infomation present in the class file to do this.
The javac exe also has a '-g' option - This option generates all debugging information, including local variables. To understand this better, I compiled a java source twice; once with the -g option and once without. I then decompiled both the class files to see how the decompiled output differs. The class file compiled with the debug option, showed all the local variable names same as in the original Java file, whereas the one without the debug option, had the local variables named by the decompiler as the local variable information was not stored in the class file.
Another interesting fact is that the class file can contain certain attributes that are non-standard; i.e. vendor specific. Suprised !!!...So was I..Please find below a snippet from the VM spec :
Compilers for Java source code are permitted to define and emit class files containing new attributes in the attributes tables of class file structures. Java Virtual Machine implementations are permitted to recognize and use new attributes found in the attributes tables of class file structures. However, all attributes not defined as part of this Java Virtual Machine specification must not affect the semantics of class or interface types. Java Virtual Machine implementations are required to silently ignore attributes they do not recognize.
For instance, defining a new attribute to support vendor-specific debugging is permitted. Because Java Virtual Machine implementations are required to ignore attributes they do not recognize, class files intended for that particular Java Virtual Machine implementation will be usable by other implementations even if those implementations cannot make use of the additional debugging information that the class files contain
When we compile a Java source using the 'javac' exe, the generated class file by default contains some debug info - By default, only the line number and source file information is generated.
Hence when a stack trace is printed on the screen, we can see the source file name and the line number also printed on the screen. Also, when using log4J, I remember using a layout which can print the line number of each log statement - I bet log4J uses the debug infomation present in the class file to do this.
The javac exe also has a '-g' option - This option generates all debugging information, including local variables. To understand this better, I compiled a java source twice; once with the -g option and once without. I then decompiled both the class files to see how the decompiled output differs. The class file compiled with the debug option, showed all the local variable names same as in the original Java file, whereas the one without the debug option, had the local variables named by the decompiler as the local variable information was not stored in the class file.
Another interesting fact is that the class file can contain certain attributes that are non-standard; i.e. vendor specific. Suprised !!!...So was I..Please find below a snippet from the VM spec :
Compilers for Java source code are permitted to define and emit class files containing new attributes in the attributes tables of class file structures. Java Virtual Machine implementations are permitted to recognize and use new attributes found in the attributes tables of class file structures. However, all attributes not defined as part of this Java Virtual Machine specification must not affect the semantics of class or interface types. Java Virtual Machine implementations are required to silently ignore attributes they do not recognize.
For instance, defining a new attribute to support vendor-specific debugging is permitted. Because Java Virtual Machine implementations are required to ignore attributes they do not recognize, class files intended for that particular Java Virtual Machine implementation will be usable by other implementations even if those implementations cannot make use of the additional debugging information that the class files contain
Friday, December 23, 2005
Select second highest record with a query
A friend of mine was asked in an interview to write a query to fetch the second highest marks in a table of students.
Well, I found out 2 ways to do this:
1) Using TOP to get the topmost 2 rows from the table in descending order and then again getting a TOP of the resultset.
SELECT TOP 1 *
FROM(SELECT TOP 2 *
FROM Table1
ORDER BY Marks desc)
ORDER BY Marks;
2) Using the MAX function. (I was suprised to see this work)
SELECT Max(Marks) FROM Table1
WHERE Marks Not In (SELECT MAX(Marks) FROM Table1);
Well, I found out 2 ways to do this:
1) Using TOP to get the topmost 2 rows from the table in descending order and then again getting a TOP of the resultset.
SELECT TOP 1 *
FROM(SELECT TOP 2 *
FROM Table1
ORDER BY Marks desc)
ORDER BY Marks;
2) Using the MAX function. (I was suprised to see this work)
SELECT Max(Marks) FROM Table1
WHERE Marks Not In (SELECT MAX(Marks) FROM Table1);
Hierarchical databases Vs Relational Databases
While designing a systems, I often came across the moot point of choosing btw a heirarchical database and a relational flat table database. There are some domain problems, where heirarchical databases such as LDAP and MS Directory Services make sense over RDBs.
The hierarchical database model existed before the far more familiar relational model in early mainframe days. Hierarchical databases were blown away by relational versions because it was difficult to model a many-to-many relationship - the very basis of the hierarchical model is that each child element has only one parent element.
In his article, Scott Ambler makes the following statement:
Hierarchical databases fell out of favor with the advent of relational databases due to their lack of flexibility because it wouldn’t easily support data access outside the original design of the data
structure. For example, in the customer-order schema you could only access an order through a customer, you couldn’t easily find all the orders that included the sale of a widget because the schema isn’t designed to all that.
I found an article on the microsoft site which discusses the areas where directory services can be used in place of Relational databases.
Some good candidates for heirarchical databases are- White pages" information, User credential & security group information, Network configuration and service policies, Application deployment policies etc.
The hierarchical database model existed before the far more familiar relational model in early mainframe days. Hierarchical databases were blown away by relational versions because it was difficult to model a many-to-many relationship - the very basis of the hierarchical model is that each child element has only one parent element.
In his article, Scott Ambler makes the following statement:
Hierarchical databases fell out of favor with the advent of relational databases due to their lack of flexibility because it wouldn’t easily support data access outside the original design of the data
structure. For example, in the customer-order schema you could only access an order through a customer, you couldn’t easily find all the orders that included the sale of a widget because the schema isn’t designed to all that.
I found an article on the microsoft site which discusses the areas where directory services can be used in place of Relational databases.
Some good candidates for heirarchical databases are- White pages" information, User credential & security group information, Network configuration and service policies, Application deployment policies etc.
Thursday, December 22, 2005
The beauty of Log4J
It took me sometime to appreciate the inheritance heirarchy in Log4J. It's quite simple to understand the Log Levels and their usage.
It is because of this heirarchy that we can have any arbitraty level of granularity in logging. For e.g. suppose we have 10 components in a distributed environment and we want to shutdown the logging of one component. This can be easily done in Log4J using config files. We can also disable logging at a class level - provided we have a Logger for that class - using the Logger.getLogger(this.class) method. Another example is if U want to switch off logging of one or more modules in a application.
We can even make dymanic changes in the configuration file at runtime and these changes would get reflected provided we have used the configureAndWatch() method.
It is because of this heirarchy that we can have any arbitraty level of granularity in logging. For e.g. suppose we have 10 components in a distributed environment and we want to shutdown the logging of one component. This can be easily done in Log4J using config files. We can also disable logging at a class level - provided we have a Logger for that class - using the Logger.getLogger(this.class) method. Another example is if U want to switch off logging of one or more modules in a application.
We can even make dymanic changes in the configuration file at runtime and these changes would get reflected provided we have used the configureAndWatch() method.
Ruminating on ClassLoaders in JVM.
One interesting point about ClassLoaders is that it is possible for the same class to be loaded separately by different class-loaders, resulting in multiple copies of the class object.
I came across a good synopsis on classloaders here : http://www.onjava.com/pub/a/onjava/2003/04/02/log4j_ejb.html
Here are some snippets from the above article:
Classloaders, as the name suggests, are responsible for loading classes within the JVM. Before your class can be executed or accessed, it must become available via a classloader. Given a class name, a classloader locates the class and loads it into the JVM. Classloaders are Java classes themselves. This brings the question: if classloaders are Java classes themselves, who or what loads them?
When you execute a Java program (i.e., by typing java at a command prompt), it executes and launches a native Java launcher. By native, I mean native to your current platform and environment. This native Java launcher contains a classloader called the bootstrap classloader. This bootstrap classloader is native to your environment and is not written in Java. The main function of the bootstrap classloader is to load the core Java classes.
The JVM implements two other classloaders by default. The bootstrap classloader loads the extension and application classloaders into memory. Both are written in Java. As mentioned before, the bootstrap classloader loads the core Java classes (for example, classes from the java.util package). The extension classloader loads classes that extend the core Java classes (e.g., classes from the javax packages, or the classes under the ext directory of your runtime). The application classloader loads the classes that make up your application.
bootstrap classloader <-- extension classloader <-- application classloader All three default classloaders follow the delegation model. Before a child classloader tries to locate a class, it delegates that task to a parent. When your application requests a particular class, the application classloader delegates this request to the extension classloader, which in turn delegates it to the bootstrap classloader. If the class that you requested is a Java core class, the bootstrap classloader will make the class available to you. However, if it cannot find the class, the request returns to the extension classloader, and from there to the application classloader itself. The idea is that each classloader first looks up to its parent for a particular class. Only if the parent does not have the class does the child classloader try to look it up itself.
In application servers, each separately-deployed web application and EJB gets its own classloader (normally; this is certainly the case in WebLogic). This classloader is derived from the application classloader and is responsible for that particular EJB or web application. This new classloader loads all classes that the webapp or EJB require that are not already part the Java core classes or the extension packages. It is also responsible for loading and unloading of classes, a feature missing from the default classloaders. This feature helps in hot deploy of applications. When WebLogic starts up, it uses the Java-supplied application classloader to load the classes that make up its runtime. It then launches individual classloaders, derived from the Java application classloader, which load the classes for individual applications. The individual classloaders are invisible to the classloaders of the other applications; hence, classes loaded for one particular application will not be seen by another application. What if you want to make a single class available to all applications? Load it in a top-level classloader. This could be in the classpath of WebLogic. When WebLogic starts, it will automatically load this class in memory using the Java-supplied application classloader. All sub-application classloaders get access to it. However, the negatives of this approach are clear too. First, you lose the capability of hot deploy for this particular class in all individual applications. Second, any change in this class means that the server needs to be restarted, as there is no mechanism for a Java application classloader to reload classes. You will need to weigh in the pros and cons before you take this approach. WebLogic Server allows you to deploy newer versions of application modules such as EJBs while the server is running. This process is known as hot-deploy or hot-redeploy and is closely related to classloading.
Java classloaders do not have any standard mechanism to undeploy or unload a set of classes, nor can they load new versions of classes. In order to make updates to classes in a running virtual machine, the classloader that loaded the changed classes must be replaced with a new classloader. When a classloader is replaced, all classes that were loaded from that classloader (or any classloaders that are offspring of that classloader) must be reloaded. Any instances of these classes must be re-instantiated.
I came across a good synopsis on classloaders here : http://www.onjava.com/pub/a/onjava/2003/04/02/log4j_ejb.html
Here are some snippets from the above article:
Classloaders, as the name suggests, are responsible for loading classes within the JVM. Before your class can be executed or accessed, it must become available via a classloader. Given a class name, a classloader locates the class and loads it into the JVM. Classloaders are Java classes themselves. This brings the question: if classloaders are Java classes themselves, who or what loads them?
When you execute a Java program (i.e., by typing java at a command prompt), it executes and launches a native Java launcher. By native, I mean native to your current platform and environment. This native Java launcher contains a classloader called the bootstrap classloader. This bootstrap classloader is native to your environment and is not written in Java. The main function of the bootstrap classloader is to load the core Java classes.
The JVM implements two other classloaders by default. The bootstrap classloader loads the extension and application classloaders into memory. Both are written in Java. As mentioned before, the bootstrap classloader loads the core Java classes (for example, classes from the java.util package). The extension classloader loads classes that extend the core Java classes (e.g., classes from the javax packages, or the classes under the ext directory of your runtime). The application classloader loads the classes that make up your application.
bootstrap classloader <-- extension classloader <-- application classloader All three default classloaders follow the delegation model. Before a child classloader tries to locate a class, it delegates that task to a parent. When your application requests a particular class, the application classloader delegates this request to the extension classloader, which in turn delegates it to the bootstrap classloader. If the class that you requested is a Java core class, the bootstrap classloader will make the class available to you. However, if it cannot find the class, the request returns to the extension classloader, and from there to the application classloader itself. The idea is that each classloader first looks up to its parent for a particular class. Only if the parent does not have the class does the child classloader try to look it up itself.
In application servers, each separately-deployed web application and EJB gets its own classloader (normally; this is certainly the case in WebLogic). This classloader is derived from the application classloader and is responsible for that particular EJB or web application. This new classloader loads all classes that the webapp or EJB require that are not already part the Java core classes or the extension packages. It is also responsible for loading and unloading of classes, a feature missing from the default classloaders. This feature helps in hot deploy of applications. When WebLogic starts up, it uses the Java-supplied application classloader to load the classes that make up its runtime. It then launches individual classloaders, derived from the Java application classloader, which load the classes for individual applications. The individual classloaders are invisible to the classloaders of the other applications; hence, classes loaded for one particular application will not be seen by another application. What if you want to make a single class available to all applications? Load it in a top-level classloader. This could be in the classpath of WebLogic. When WebLogic starts, it will automatically load this class in memory using the Java-supplied application classloader. All sub-application classloaders get access to it. However, the negatives of this approach are clear too. First, you lose the capability of hot deploy for this particular class in all individual applications. Second, any change in this class means that the server needs to be restarted, as there is no mechanism for a Java application classloader to reload classes. You will need to weigh in the pros and cons before you take this approach. WebLogic Server allows you to deploy newer versions of application modules such as EJBs while the server is running. This process is known as hot-deploy or hot-redeploy and is closely related to classloading.
Java classloaders do not have any standard mechanism to undeploy or unload a set of classes, nor can they load new versions of classes. In order to make updates to classes in a running virtual machine, the classloader that loaded the changed classes must be replaced with a new classloader. When a classloader is replaced, all classes that were loaded from that classloader (or any classloaders that are offspring of that classloader) must be reloaded. Any instances of these classes must be re-instantiated.
Wednesday, December 21, 2005
O/R mapping tools
I have had some experience with some O/R mapping tools such as TopLink and Hibernate.
But I did not know that the market is flooded with a variety of OR tools.
Here are a few of them:
Abra - http://abra.sourceforge.net
BasicWebLib - http://basicportal.sourceforge.net/
Castor - http://castor.exolab.org
Cayenne - http://objectstyle.org/cayenne/
DataBind - http://databind.sourceforge.net
DB VisualArchitect - http://www.visual-paradigm.com/dbva.php
EnterpriseObjectsFramework - http://www.apple.com/webobjects/
Expresso - http://www.jcorporate.com
FireStorm - http://www.codefutures.com/products/firestorm
Hibernate - http://www.hibernate.org
Hydrate - http://hydrate.sourceforge.net
iBATIS DB Layer - http://www.ibatis.com
Infobjects ObjectDRIVER- http://www.infobjects.com
InterSystems Cache - http://www.intersystems.com
Jakarta ObjectRelationalBridge - http://db.apache.org/ojb
Java Ultra-Lite Persistence (JULP) - http://julp.sourceforge.net
Jaxor - http://jaxor.sourceforge.net
JdoGenie - http://www.jdogenie.com
JDOMax - http://www.jdomax.com
JDX - http://www.softwaretree.com
KodoJdo - http://www.solarmetric.com/Software/Kodo_JDO/
LiDO - http://www.libelis.com
O/R Broker - http://orbroker.sourceforge.net/
Persistence EdgeXtend - http://www.persistence.com/products/edgextend/
PlanetJ's WOW = http://planetjavainc.com/wow.html
PowerMapJdo - http://www.powermapjdo.com
Signsoft intelliBO - http://www.intellibo.com
SimpleOrm - http://www.SimpleOrm.org
SpadeSoft XJDO - http://www.spadesoft.com
Sql2java - http://sql2java.sf.net
Sun Microsystem certified (SunTone?) - FrontierSuite? for J2EE & J2SE - http://www.objectfrontier.com
Sun Microsystem certified (SunTone?) - FrontierSuite? for JDO - http://www.objectfrontier.com
The ProductivityEnvironmentForJava (PE:J) - http://www.hywy.com/
TopLink - http://otn.oracle.com/products/ias/toplink/content.html
VBSF - http://www.objectmatter.com
Also the following articles give some some good introduction to O-R mapping tools and their comparisions:
http://c2.com/cgi-bin/wiki?ObjectRelationalToolComparison
http://www.agiledata.org/essays/mappingObjects.html
http://madgeek.com/Articles/ORMapping/EN/mapping.htm
But I did not know that the market is flooded with a variety of OR tools.
Here are a few of them:
Abra - http://abra.sourceforge.net
BasicWebLib - http://basicportal.sourceforge.net/
Castor - http://castor.exolab.org
Cayenne - http://objectstyle.org/cayenne/
DataBind - http://databind.sourceforge.net
DB VisualArchitect - http://www.visual-paradigm.com/dbva.php
EnterpriseObjectsFramework - http://www.apple.com/webobjects/
Expresso - http://www.jcorporate.com
FireStorm - http://www.codefutures.com/products/firestorm
Hibernate - http://www.hibernate.org
Hydrate - http://hydrate.sourceforge.net
iBATIS DB Layer - http://www.ibatis.com
Infobjects ObjectDRIVER- http://www.infobjects.com
InterSystems Cache - http://www.intersystems.com
Jakarta ObjectRelationalBridge - http://db.apache.org/ojb
Java Ultra-Lite Persistence (JULP) - http://julp.sourceforge.net
Jaxor - http://jaxor.sourceforge.net
JdoGenie - http://www.jdogenie.com
JDOMax - http://www.jdomax.com
JDX - http://www.softwaretree.com
KodoJdo - http://www.solarmetric.com/Software/Kodo_JDO/
LiDO - http://www.libelis.com
O/R Broker - http://orbroker.sourceforge.net/
Persistence EdgeXtend - http://www.persistence.com/products/edgextend/
PlanetJ's WOW = http://planetjavainc.com/wow.html
PowerMapJdo - http://www.powermapjdo.com
Signsoft intelliBO - http://www.intellibo.com
SimpleOrm - http://www.SimpleOrm.org
SpadeSoft XJDO - http://www.spadesoft.com
Sql2java - http://sql2java.sf.net
Sun Microsystem certified (SunTone?) - FrontierSuite? for J2EE & J2SE - http://www.objectfrontier.com
Sun Microsystem certified (SunTone?) - FrontierSuite? for JDO - http://www.objectfrontier.com
The ProductivityEnvironmentForJava (PE:J) - http://www.hywy.com/
TopLink - http://otn.oracle.com/products/ias/toplink/content.html
VBSF - http://www.objectmatter.com
Also the following articles give some some good introduction to O-R mapping tools and their comparisions:
http://c2.com/cgi-bin/wiki?ObjectRelationalToolComparison
http://www.agiledata.org/essays/mappingObjects.html
http://madgeek.com/Articles/ORMapping/EN/mapping.htm
Tuesday, December 20, 2005
Is Swing really slow?
Often I have heard people complain that Swing Apps are slow. I also have had some bad experiences with slow Swing Apps, but then I have also seen some very cool high performant applications. So, what's the secret of these fast Swing apps. I think the reason can be found in James Gosling's answer:
The big problem that Swing has is that it's big and complicated. And the reason that it's big and complicated is that it is the most fully featured, flexible, whatever-way-you-want-to-measure-it UI [user interface] tool kit on the planet. You can do the most amazing things with Swing. It's sort of the 747 cockpit of UI design tool kits, and flying a 747 is a little intimidating, and what people really want is a Cessna.
It is definately possible to write good speedy Swing applications, but U need to be a master of Swing and threading and know all the potholes which hog memory.
Here are a few links which contain some good info on fast Swing apps:
http://www.swingwiki.org/table_of_contents
http://www.javalobby.org/articles/swing_slow/index.jsp
http://www.clientjava.com/blog
http://www.javaworld.com/channel_content/jw-awt-index.shtml
http://www.javalobby.org/eps/galbraith-swing-1/index.html
The big problem that Swing has is that it's big and complicated. And the reason that it's big and complicated is that it is the most fully featured, flexible, whatever-way-you-want-to-measure-it UI [user interface] tool kit on the planet. You can do the most amazing things with Swing. It's sort of the 747 cockpit of UI design tool kits, and flying a 747 is a little intimidating, and what people really want is a Cessna.
It is definately possible to write good speedy Swing applications, but U need to be a master of Swing and threading and know all the potholes which hog memory.
Here are a few links which contain some good info on fast Swing apps:
http://www.swingwiki.org/table_of_contents
http://www.javalobby.org/articles/swing_slow/index.jsp
http://www.clientjava.com/blog
http://www.javaworld.com/channel_content/jw-awt-index.shtml
http://www.javalobby.org/eps/galbraith-swing-1/index.html
Wednesday, December 14, 2005
Duplicate Form Submission and the Synchronizer Token pattern
The Synchronizer Token pattern addresses the problem of duplicate form submissions. A synchronizer token is set in a user's session and included with each form returned to the client. When that form is submitted, the synchronizer token in the form is compared to the synchronizer token in the session. The tokens should match the first time the form is submitted. If the tokens do not match, then the form submission may be disallowed and an error returned to the user. Token mismatch may occur when the user submits a form, then clicks the Back button in the browser and attempts to resubmit the same form.
On the other hand, if the two token values match, then we are confident that the flow of control is exactly as expected. At this point, the token value in the session is modified to a new value and the form submission is accepted.
Struts has inbuild support for the Synchronizer Token pattern. Method such as "saveToken()" and "isTokenValid()" are present in the ActionForm class.
Other ways of preventing a duplicate submit is using javascript to disable the submit button after it has been pressed once. But this does not work well with all browsers.
On the other hand, if the two token values match, then we are confident that the flow of control is exactly as expected. At this point, the token value in the session is modified to a new value and the form submission is accepted.
Struts has inbuild support for the Synchronizer Token pattern. Method such as "saveToken()" and "isTokenValid()" are present in the ActionForm class.
Other ways of preventing a duplicate submit is using javascript to disable the submit button after it has been pressed once. But this does not work well with all browsers.
Proxy setting for .NET programs
To access an internet site thru a .NET program U may have to go thru Ur company proxy.
Here's the sample code for doing so:
string query="http://narencoolgeek.blogspot.com";
WebProxy proxyObj = new WebProxy("10.10.111.19", 8080) ;
NetworkCredential networkCredential = new NetworkCredential("username", "secret_password") ;
HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create(query) ; proxyObj.Credentials = networkCredential ;
req.Proxy = proxyObj ;
For proxy setting in Java programs click here.
Here's the sample code for doing so:
string query="http://narencoolgeek.blogspot.com";
WebProxy proxyObj = new WebProxy("10.10.111.19", 8080) ;
NetworkCredential networkCredential = new NetworkCredential("username", "secret_password") ;
HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create(query) ; proxyObj.Credentials = networkCredential ;
req.Proxy = proxyObj ;
For proxy setting in Java programs click here.
Locking in Databases
Databases support different types of locking strategies. We have optimistic locking strategies where concurrency would be more, but data integrity would be less. We have pessimistic locking strategies where concurrency is less, but there is more data integrity. Basically when it comes to locking and transaction isolation levels, its a trade-off between data integrity and concurrency.
Databases supports various levels of lock granularity. The lowest level is a single row. Sometimes, the database doesn't have enough resources to lock each individual
row. In such cases, the database can acquire locks on a single data or index page, group of pages, or an entire table. The granularity of locks depends on the memory available to the database. Servers with more memory can support more concurrent users because they can acquire and release more locks.
We can give locking hints to the database while sending queries that would help us override locking decisions made by the database. For instance, in SQL Server. we can specify the ROWLOCK hint with the UPDATE statement to convince SQL Server to lock each row affected by that data modification.
While dealing with transactions, the type of locking used depends on the Transaction Isolation Level specified for that particular transaction.
SQL Server supports implicit and explicit transactions. By default, each INSERT, UPDATE, and DELETE statement runs within an implicit transaction.Explicit transactions, on the other hand, must be specified by the programmer. Such transactions are included in
BEGIN TRANSACTION ... COMMIT TRANSACTION block
There are two common types of locks present in all databases- Shared locks and Exclusive locks.
Shared locks (S) allow transactions to read data with SELECT statements. Other connections are allowed to read the data at the same time; however, no transactions are allowed to modify data until the shared locks are released.
Exclusive locks (X) completely lock the resource from any type of access including reads. They are issued when data is being modified through INSERT, UPDATE and DELETE statements
Locking/Transaction Isolation levels solve the following concurrency problems:
Databases supports various levels of lock granularity. The lowest level is a single row. Sometimes, the database doesn't have enough resources to lock each individual
row. In such cases, the database can acquire locks on a single data or index page, group of pages, or an entire table. The granularity of locks depends on the memory available to the database. Servers with more memory can support more concurrent users because they can acquire and release more locks.
We can give locking hints to the database while sending queries that would help us override locking decisions made by the database. For instance, in SQL Server. we can specify the ROWLOCK hint with the UPDATE statement to convince SQL Server to lock each row affected by that data modification.
While dealing with transactions, the type of locking used depends on the Transaction Isolation Level specified for that particular transaction.
SQL Server supports implicit and explicit transactions. By default, each INSERT, UPDATE, and DELETE statement runs within an implicit transaction.Explicit transactions, on the other hand, must be specified by the programmer. Such transactions are included in
BEGIN TRANSACTION ... COMMIT TRANSACTION block
There are two common types of locks present in all databases- Shared locks and Exclusive locks.
Shared locks (S) allow transactions to read data with SELECT statements. Other connections are allowed to read the data at the same time; however, no transactions are allowed to modify data until the shared locks are released.
Exclusive locks (X) completely lock the resource from any type of access including reads. They are issued when data is being modified through INSERT, UPDATE and DELETE statements
Locking/Transaction Isolation levels solve the following concurrency problems:
- Lost Updates: Lost updates occur when two or more transactions select the same row and then update the row based on the value originally selected. Each transaction is unaware of other transactions. The last update overwrites updates made by the other transactions, which results in lost data.
- Dirty Read: Uncommitted dependency occurs when a second transaction selects a row that is being updated by another transaction. The second transaction is reading data that has not been committed yet and may be changed by the transaction updating the row.
- Nonrepeatable Read: Inconsistent analysis occurs when a second transaction accesses the same row several times and reads different data each time.
- Phantom reads: These occur when an insert or delete action is performed against a row that belongs to a range of rows being read by a transaction. The transaction's first read of the range of rows shows a row that no longer exists in the second or succeeding read, as a result of a deletion by a different transaction. Similarly, as the result of an insert by a different transaction, the transaction's second or succeeding read shows a row that did not exist in the original read.
These concurrency problems can be solved using the correct transaction isolation level in our programs. To balance between high concurrency and data integrity, we can choose from the following isolation levels:
- READ UNCOMMITTED: This is the lowest level where transactions are isolated only enough to ensure that physically corrupt data is not read. Does not protect against dirty read, phantom read or non-repeatable reads.
- READ COMMITTED: The shared lock is held for the duration of the transaction, meaning that no other transactions can change the data at the same time. Protects against dirty reads, but the other problems remain.
- REPEATABLE READ: This setting disallows dirty and non-repeatable reads. But phantom reads are still possible.
- SERIALIZABLE: This is the highest level, where transactions are completely isolated from one another. Protects against dirty read, phantom read and non-repeatable read.
There are other types of locks available in the database such as 'update lock', 'intent lock', 'schema lock' etc. The update lock prevents deadlocks in the database. For more information about these check out the following links:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/acdata/ac_8_con_7a_6fhj.asp
http://www.awprofessional.com/articles/article.asp?p=26890&rl=1
Tuesday, December 13, 2005
Deleting duplicate rows from a table
This seems to a favourite question during interviews - How to delete duplicate rows in a table?
Well, we can have many strategies:
- Capture one instance of the unique rows using a SELECT DISTINCT .., and dump the results into a temp table. Delete all of the rows from the original table and then insert the rows from the temp table back into the original table.
- If there is an identity column, the we can also write a query to get all the rows that have duplicate entries :
SELECT Field1, Field2, Count(ID)
FROM Foo1
GROUP BY Foo1.Field1, Foo1.Field2
HAVING Count(Foo1.ID) > 1
-----------------------------
Then loop thru the resultset and get a cursor for the query
"SELECT Field1, Field2, ID
FROM Foo1
WHERE Field1 = @FIELD1 and Field2 = @FIELD2".
Use the cursor to delete all the duplicate rows returned except one.
The following links discuss the above techniques and some more:
sql-server-performance
databasejournal
aspfaqs
Well, we can have many strategies:
- Capture one instance of the unique rows using a SELECT DISTINCT .., and dump the results into a temp table. Delete all of the rows from the original table and then insert the rows from the temp table back into the original table.
- If there is an identity column, the we can also write a query to get all the rows that have duplicate entries :
SELECT Field1, Field2, Count(ID)
FROM Foo1
GROUP BY Foo1.Field1, Foo1.Field2
HAVING Count(Foo1.ID) > 1
-----------------------------
Then loop thru the resultset and get a cursor for the query
"SELECT Field1, Field2, ID
FROM Foo1
WHERE Field1 = @FIELD1 and Field2 = @FIELD2".
Use the cursor to delete all the duplicate rows returned except one.
The following links discuss the above techniques and some more:
sql-server-performance
databasejournal
aspfaqs
Thursday, December 08, 2005
Tools used in SDLC
I decided to list down all the available tools for different phases of a SDLC. Here it goes:
Requirements Management:
- DOORS: Dynamic Object Oriented Requirements System
- RequisitePro : A requirements management tool from Rational Software
- Requirements Traceability Management (RTM)
Design:
- ArgoUML: http://argouml.tigris.org/
-Rational Rose http://www.rationalrose.com/
-Enterprise Architect http://www.sparxsystems.com.au/
-Rhapsody http://www.ilogix.com/homepage.aspx
-ERwin http://www3.ca.com/solutions/Product.aspx?ID=260
-Rational Rose Real Time http://www-128.ibm.com/developerworks/rational/products/rose
-Describe http://www.embarcadero.com/products/describe/
-MagicDraw http://www.magicdraw.com/
-SmartDraw: http://www.smartdraw.com/examples/software-erd/
-Visio : http://www.mvps.org/visio/
Code Generation:
-OptimalJ: http://www.compuware.com/products/optimalj/
- Rational Application Developer
-Object Frontier
-JVider is Java Visual Interface Designer which helps with GUI building for Swing applications
Unit Testing:
-Jtest: http://www.parasoft.com/jsp/home.jsp
-JUnit: http://www.junit.org/
Load Testing:
SilkPerformer is load performance testing tool.
LoadRunner
JMeter
ANTS Load
Microsoft Web Application Stress Tool
Web Testing/ GUI testing:
SilkTest from Segue Software
Rational ROBOT
WinRunner
Configuration Management Tools:
Concurrent Version System - CVS
Subversion
Clearcase
Visual SourceSafe
Documentation:
Framemaker
Will keep augmenting this list...
Requirements Management:
- DOORS: Dynamic Object Oriented Requirements System
- RequisitePro : A requirements management tool from Rational Software
- Requirements Traceability Management (RTM)
Design:
- ArgoUML: http://argouml.tigris.org/
-Rational Rose http://www.rationalrose.com/
-Enterprise Architect http://www.sparxsystems.com.au/
-Rhapsody http://www.ilogix.com/homepage.aspx
-ERwin http://www3.ca.com/solutions/Product.aspx?ID=260
-Rational Rose Real Time http://www-128.ibm.com/developerworks/rational/products/rose
-Describe http://www.embarcadero.com/products/describe/
-MagicDraw http://www.magicdraw.com/
-SmartDraw: http://www.smartdraw.com/examples/software-erd/
-Visio : http://www.mvps.org/visio/
Code Generation:
-OptimalJ: http://www.compuware.com/products/optimalj/
- Rational Application Developer
-Object Frontier
-JVider is Java Visual Interface Designer which helps with GUI building for Swing applications
Unit Testing:
-Jtest: http://www.parasoft.com/jsp/home.jsp
-JUnit: http://www.junit.org/
Load Testing:
SilkPerformer is load performance testing tool.
LoadRunner
JMeter
ANTS Load
Microsoft Web Application Stress Tool
Web Testing/ GUI testing:
SilkTest from Segue Software
Rational ROBOT
WinRunner
Configuration Management Tools:
Concurrent Version System - CVS
Subversion
Clearcase
Visual SourceSafe
Documentation:
Framemaker
Will keep augmenting this list...
Cool Free Data Models
While browsing the web, I came across this cool site which has over 200 data-models samples.
Great for anyone who wants to learn about data-modelling or have a template for a given problem domain.
The link is here : http://www.databaseanswers.org/data_models/index.htm
Some interesting data models I found in this site are - datamodels for Hierarchies , e-commerce etc. Worth a perusal.
Great for anyone who wants to learn about data-modelling or have a template for a given problem domain.
The link is here : http://www.databaseanswers.org/data_models/index.htm
Some interesting data models I found in this site are - datamodels for Hierarchies , e-commerce etc. Worth a perusal.
Data Modelling Vs OO Modelling
While working on projects, often I had tussles with erst-while database developers who used to drive the design of the system using Data Models. Most of them came from non-OO background and were apt in ER diagrams. But the porblem is that a Data Model cannot and should not drive the OO model. I came across this excellent article by Scott Ambler discussing this dilemma.
http://www.agiledata.org/essays/drivingForces.html
In the above article, the author argues that object schemas can be quite different from physical data schemas. Using two lucid examples he shows how different object schemas can map to the same data schema and how it is possible for a single object schema to correctly map to several data schemas.
There are situations where OO varies significantly from ERD, for example in cases of inheritance and non-persistent classes.
Aslo, OO models can convey more specification on the class diagram in representing certain things like associations than ERD can.
I personally believe that if U are building a OO system, then we should first go for OO Class modelling and then think about resolving the OO-relational database impedance mismatch.
http://www.agiledata.org/essays/drivingForces.html
In the above article, the author argues that object schemas can be quite different from physical data schemas. Using two lucid examples he shows how different object schemas can map to the same data schema and how it is possible for a single object schema to correctly map to several data schemas.
There are situations where OO varies significantly from ERD, for example in cases of inheritance and non-persistent classes.
Aslo, OO models can convey more specification on the class diagram in representing certain things like associations than ERD can.
I personally believe that if U are building a OO system, then we should first go for OO Class modelling and then think about resolving the OO-relational database impedance mismatch.
What are Multi-dimensional databases?
A multidimensional database (MDB) is a type of database that is optimized for data warehouse and online analytical processing (OLAP) applications. Multidimensional databases are frequently created using input from existing relational databases.
A multidimensional database - or a multidimensional database management system (MDDBMS) - implies the ability to rapidly process the data in the database so that answers can be generated quickly. A number of vendors provide products that use multidimensional databases. Approaches to how data is stored and the user interface vary.
Conceptually, a multidimensional database uses the idea of a data cube to represent the dimensions of data available to a user. For example, "sales" could be viewed in the dimensions of product model, geography, time, or some additional dimension. In this case, "sales" is known as the measure attribute of the data cube and the other dimensions are seen as feature attributes. Additionally, a database creator can define hierarchies and levels within a dimension (for example, state and city levels within a regional hierarchy).
More information can be at:
http://flame.cs.dal.ca/~panda/overview.html
http://www.dba-oracle.com/cou_mdb_class.htm
A multidimensional database - or a multidimensional database management system (MDDBMS) - implies the ability to rapidly process the data in the database so that answers can be generated quickly. A number of vendors provide products that use multidimensional databases. Approaches to how data is stored and the user interface vary.
Conceptually, a multidimensional database uses the idea of a data cube to represent the dimensions of data available to a user. For example, "sales" could be viewed in the dimensions of product model, geography, time, or some additional dimension. In this case, "sales" is known as the measure attribute of the data cube and the other dimensions are seen as feature attributes. Additionally, a database creator can define hierarchies and levels within a dimension (for example, state and city levels within a regional hierarchy).
More information can be at:
http://flame.cs.dal.ca/~panda/overview.html
http://www.dba-oracle.com/cou_mdb_class.htm
Tuesday, December 06, 2005
Ruminating on Database Cursors
Cursors are database objects that allow us to manipulate data in a set in a row-by-row basis or on a group of rows at one time. Cursors are quite popular among database developers as the row can be updated at the same time itself. There is no need to fire a separate SQL query.
But there is also a lot of confusion regarding the exact definition of cursors, because different people use it in different contexts. For e.g. when a database administrator talks of cursors, he means the server-side cursor he uses inside stored procedures. But if a JDBC application developer talks about a cursor, he may mean the pointer in the JDBC ResultSet object.
I did a bit of reseach on the web, and finally cleared a few cobwebs from the head. Here's a snapshot of what I learned:
ResultSet srs = stmt.executeQuery("SELECT COF_NAME, PRICE FROM COFFEES");
---------------------------------------------------------------------------------
The above code makes the ResultSet as scroll-sensitive, so it will reflect changes made to it while it is open. This is the equivalent of a dynamic cursor. In a dynamic cursor, the engine repeats the query each time the cursor is accessed so new members are added and existing members are removed as the database processes changes to the database.
The second argument is one of two ResultSet constants for specifying whether a result set is read-only or updatable: CONCUR_READ_ONLY and CONCUR_UPDATABLE.
Specifying the constant TYPE_FORWARD_ONLY creates a nonscrollable result set, that is, one in which the cursor moves only forward. If you do not specify any constants for the type and updatability of a ResultSet object, you will automatically get one that is TYPE_FORWARD_ONLY and CONCUR_READ_ONLY (as is the case when you are using only the JDBC 1.0 API). You might keep in mind, though, the fact that no matter what type of result set you specify, you are always limited by what your DBMS and driver actually provide.
But there is also a lot of confusion regarding the exact definition of cursors, because different people use it in different contexts. For e.g. when a database administrator talks of cursors, he means the server-side cursor he uses inside stored procedures. But if a JDBC application developer talks about a cursor, he may mean the pointer in the JDBC ResultSet object.
I did a bit of reseach on the web, and finally cleared a few cobwebs from the head. Here's a snapshot of what I learned:
- There are implicit cursors and explicit cursors. An implicit cursor is - well, that's just a piece of memory used by the database server to work with resulsets internally. Implicit cursors are not accessible via an externally exposed API, whereas explicit cursors are.
- Server-side cursors and Client-side cursors: The difference between a client-side cursor and a server-side cursor in classic ADO is substantial and can be confusing. A server-side cursor allows you to manipulate rows on the server through calls on the client, usually storing all or a portion of the data in TEMPDB. The client-side cursor fetches data into a COM object on the client. Its name comes from the fact that the buffered data on the client exhibits cursor-like behaviors you can scroll through and, potentially, update it. The behavior difference manifests itself in a few ways. Fetching a large resultset into a client cursor causes a big performance hit on the initial fetch, and server cursors result in increased memory requirements for SQL Server and require a dedicated connection all the time you're fetching. Client-side cursors can be dangerous because using them has the side effect of retrieving all records from the server that are a result of your command/SQL statement. If you execute a procedure or SQL statement that could retrieve 10,000 records, and use a client-side cursor, you had better have enough memory to hold 10,000 records on the client. Also, control will not return to your code/application until all of these records are retrieved from the server, which can make your application appear slow to users. If you suspect that you are going to retrieve a large number of rows, client-side cursors are not the way to go.
- DYNAMIC, STATIC, and KEYSET cursors: Dynamic cursors will show changes made on the base table as you scroll through the cursor. Static cursors copy the base table, to the tempdb. The cursor then reads from the tempdb, so any changes happening on the base table will not be reflected in the cursors scrolling. Keysets are in between Dynamic and Static cursors. A keyset will copy the base table's selected records keys into the tempdb, so the cursor will select the rows from the tempdb, but the data from the base table. So change to the base table will be seen, but new record inserts will not be.
Next, I tried to find out how these cursors can be manipulated using .NET and Java APIs.
In .NET, the DataReader object acts as a wrapper class for a server-side cursor. The DataReader provides a read-only and forward-only cursor. More info about this is here.
In JDBC, we handle everything using ResultSet objects. Since JDBC 2.0/3.0, we have ResultSets that are scrollable backwards and also that allow update operations. So I believe if U configure a ResultSet to be scrollable backwards and allow update opeartions, U are essentially dealing with a server-side cursor.
Code snippet:
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_READ_ONLY);ResultSet srs = stmt.executeQuery("SELECT COF_NAME, PRICE FROM COFFEES");
---------------------------------------------------------------------------------
The above code makes the ResultSet as scroll-sensitive, so it will reflect changes made to it while it is open. This is the equivalent of a dynamic cursor. In a dynamic cursor, the engine repeats the query each time the cursor is accessed so new members are added and existing members are removed as the database processes changes to the database.
The second argument is one of two ResultSet constants for specifying whether a result set is read-only or updatable: CONCUR_READ_ONLY and CONCUR_UPDATABLE.
Specifying the constant TYPE_FORWARD_ONLY creates a nonscrollable result set, that is, one in which the cursor moves only forward. If you do not specify any constants for the type and updatability of a ResultSet object, you will automatically get one that is TYPE_FORWARD_ONLY and CONCUR_READ_ONLY (as is the case when you are using only the JDBC 1.0 API). You might keep in mind, though, the fact that no matter what type of result set you specify, you are always limited by what your DBMS and driver actually provide.
Monday, December 05, 2005
Quick HEX dump utility in DOS
Recently, I wanted to see the hex dump of a binary file on a server. The server machine did not have my favourite hex GUI editors. I struggled to download a hex dump utility from the web, when my friend showed me how to use the 'debug.exe' tool in DOS to get a hex dump of a file.
On the DOS prompt type :
C:\>debug
-d
-----------------------
The 'd' (dump) option would dump the first 128 bytes. Typing 'd' again would give the hex dump of the next block of bytes.
U can type '?' to get a list of all the commands. Type 'q' to quit from debug mode.
On the DOS prompt type :
C:\>debug
-d
-----------------------
The 'd' (dump) option would dump the first 128 bytes. Typing 'd' again would give the hex dump of the next block of bytes.
U can type '?' to get a list of all the commands. Type 'q' to quit from debug mode.
Subscribe to:
Posts (Atom)